|
✂️ Cut your QA cycles down to minutes with automated testing (Sponsored)
 |
If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
Disclaimer: The details in this post have been derived from the details shared online by the Lyft Engineering Team. All credit for the technical details goes to the Lyft Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them
When you request a ride on Lyft, dozens of machine learning models spring into action behind the scenes. One model may calculate the price of your trip. Another determines which drivers should receive bonus incentives. A fraud detection model scans the transaction for suspicious activity. An ETA prediction model estimates your arrival time. All of this happens in milliseconds, and it happens millions of times every single day.
The engineering challenge of serving machine learning models at this scale is immense.
Lyft’s solution was to build a system called LyftLearn Serving that makes this task easy for developers. In this article, we will look at how Lyft built this platform and the architecture behind it.
Two Planes of Complexity
Lyft identified that machine learning model serving is difficult because of the complexity on two different planes:
The first plane is the data plane. This encompasses everything that happens during steady-state operation when the system is actively processing requests. This includes network traffic, CPU, and memory consumption. Also, the model must load into memory and execute the inference tasks quickly. In other words, these are the runtime concerns that determine whether the system can handle production load.
The second plane is the control plane, which deals with everything that changes over time. For example, models need to be deployed and undeployed. They need to be retrained on fresh data and versioned properly. New models need to be tested through experiments before fully launching. Also, backward compatibility must be maintained so that changes don’t break existing functionality.
Lyft needed to excel at both simultaneously while supporting a diverse set of requirements across dozens of teams.
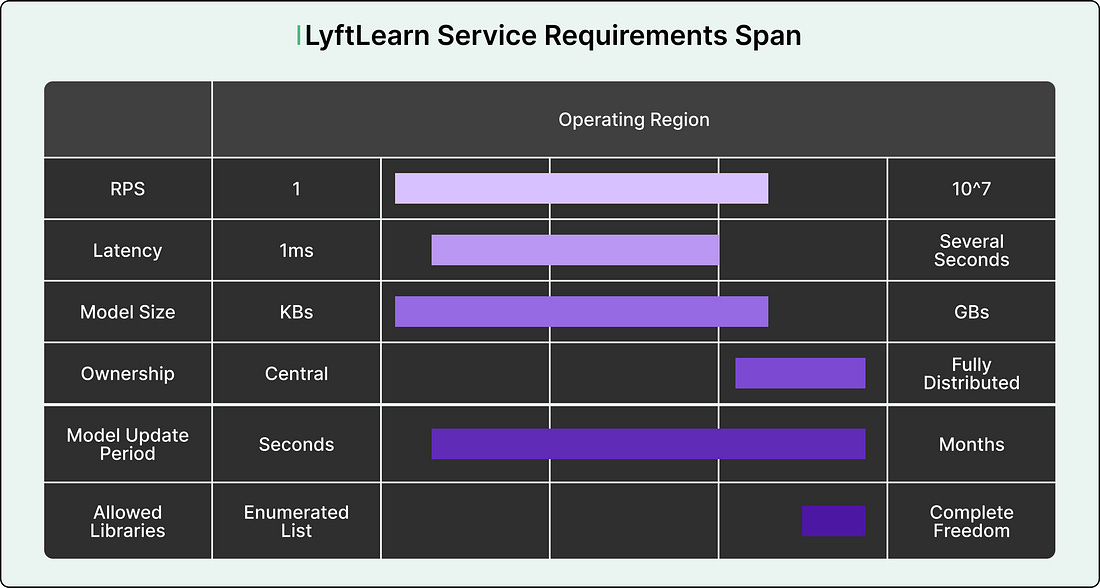
The Requirements Problem
The diversity of requirements at Lyft made building a one-size-fits-all solution nearly impossible. Different teams cared about wildly different system characteristics, creating a vast operating environment.
For example, some teams required extremely tight latency limits. Their models needed to return predictions in single-digit milliseconds because any delay would degrade user experience. Other teams cared more about throughput, needing to handle over a million requests per second during peak hours. Some teams wanted to use niche machine learning libraries that weren’t widely supported. Others needed continual learning capabilities, where models update themselves in real-time based on new data.
See the diagram below:
 |
To make matters worse, Lyft already had a legacy monolithic serving system in production. While this system worked for some use cases, its monolithic design created serious problems.
All teams shared the same codebase, which meant they had to agree on which versions of libraries to use. One team’s deployment could break another team’s models. During incidents, it was often unclear which team owned which part of the system. Teams frequently blocked each other from deploying changes.