|
 |
👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’ve been forwarded this email, you can subscribe here.
How AWS deals with a major outage
What happens when there’s a massive outage at AWS? A member of AWS’s Incident Response team lifts the lid, after playing a key role in resolving the leading cloud provider’s most recent major outage
In October, the largest Amazon Web Services (AWS) region in the world suffered an outage lasting 15 hours, which created a global impact as thousands of sites and apps crashed or degraded – including Amazon.com, Signal, Snapchat, and others.
AWS released an incident summary three days later, revealing the outage in us-east-1 was started by a failure inside DynamoDB’s DNS system, which then spread to Amazon EC2 and to AWS’s Network Load Balancer. The incident summary overlooked questions such as why it took so long to resolve, and some media coverage sought to fill the gap.
The Register claimed that an “Amazon brain drain finally sent AWS down the spout”, because some AWS staff who knew the systems inside out had quit the company, and their institutional knowledge was sorely missed.
For more clarity and detail, I went to an internal source at Amazon: Senior Principal Engineer, Gavin McCullagh, who was part of the crew which resolved this outage from start to finish. In this article, Gavin shares his insider perspective and some new details about what happened, and we find out how incident response works at the company.
This article is based on Gavin’s account of the incident to me. We cover:
Incident Response team at AWS. An overview of how global incident response works at the leading cloud provider, and a summary of Gavin’s varied background at AWS.
Mitigating the outage (part 1). Rapid triage, two simultaneous problems, and extra details on how the DynamoDB outage was eventually resolved.
What caused the outage? An unlucky, unexpected lock contention across the three DNS enactors started it all. Also, a clever usage of Route 53 as an optimistic locking mechanism.
Oncall tooling & outage coordination. Amazon’s outage severity scale, tooling used for paging and incident management, and why 3+ parallel calls are often run during a single outage.
Mitigating the outage (part 2). After the DynamoDB outage was mitigated, the EC2 and Network Load Balancer (NLB) had issues that took hours to resolve.
Post-incident. The typical ops review process at AWS, and how improvements after a previous major outage in 2023 helped to contain this one.
Improvements and learnings. Changes that AWS is making to its services, and how the team continues to learn how to handle metastable failures better. Also, there’s a plan to use formal methods for verification, even for systems like DynamoDB’s DNS services.
Spoiler alert: this outage was not caused by a brain drain. In fact, many engineers who originally built the service, DNS Enactor (responsible for updating routes in Amazon’s DNS service) ~3 years ago, are very much still at AWS, and five of them hopped onto the outage call in the dead of night, which likely helped to resolve the outage more quickly.
As it turns out – and as readers of this newsletter likely already know! – operating distributed systems is simply hard, and it’s even harder when several things go wrong at once.
Note: if you work at Amazon, get full access to The Pragmatic Engineer with your corporate email here. It includes deepdives like Inside Amazon’s Engineering Culture, ones on Meta, Stripe, and Google, and a wide variety of engineering culture deepdives.
The bottom of this article could be cut off in some email clients. Read the full article uninterrupted, online.
1. Incident Response team at AWS
Amazon is made up of many different businesses of which the best known are:
Amazon Retail: operates the shopping websites Amazon.com, and 21 regional versions including Amazon.co.uk, Amazon.de, and others.
AWS: everything to do with Amazon Web Services. Retail is a major customer of AWS.
These organizations operate pretty much independently with their own processes and set ups. Processes are similar but not identical, and both groups evolve how they work over time, separately. In this deepdive, our sole focus is AWS, but it could be assumed Retail has some similar functions, like separate Incident Response teams.
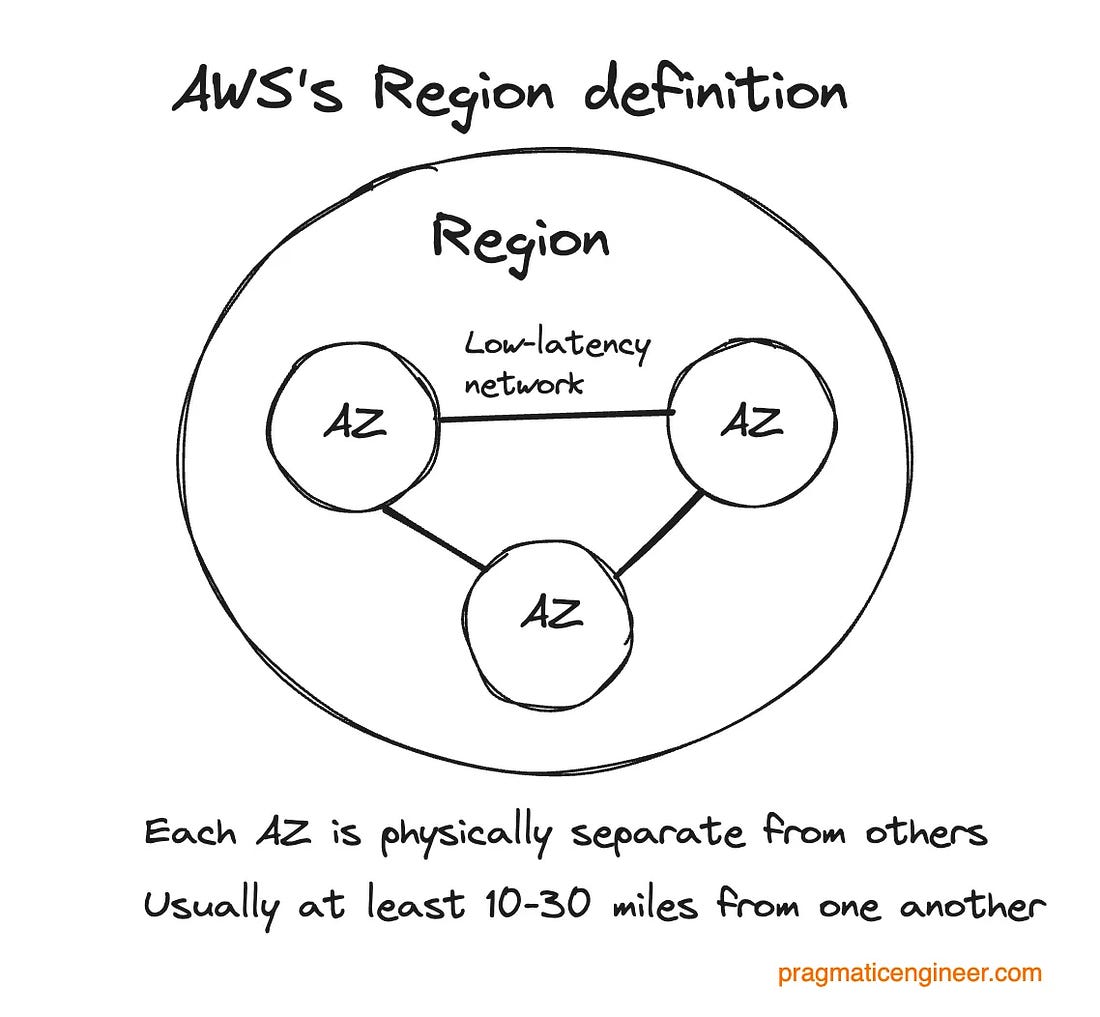
Regions and AZs: AWS is made up of 38 cloud regions. Each one consists of at least 3 Availability Zones (AZs), which are at least one independent data center, connected via a low-latency network. Note: “Region” and “AZ” mean slightly different things among cloud providers, as covered in Three cloud providers, three outages, three different responses.