|
Ditch the vibes, get the context (Sponsored)
 |
Your team ships to production; vibes won’t cut it. Augment Code’s powerful AI coding agent and industry-leading context engine meet professional development teams exactly where they are, delivering production-grade features and deep context into even the largest and gnarliest codebases.
With Augment your team can:
index and navigate millions of lines of code
get instant answers about any part of your codebase
automate processes across your entire development stack
build with the AI agent that gets you, your team, and your code
Ditch the vibes and get the context you need to engineer what’s next.
Imagine spending an hour working with an LLM to debug a complex piece of code.
The conversation has been productive, with the AI helping identify issues and suggest solutions. Then, when referencing “the error we discussed earlier,” the AI responds as if the entire previous discussion never happened. It asks for clarification about which error, seemingly having forgotten everything that came before. Or worse, it hallucinates and provides a made-up response. This frustrating experience can leave users wondering if something went wrong.
This memory problem isn’t a bug or a temporary glitch. It’s a fundamental architectural constraint that affects every Large Language Model (LLM) available today to some extent.
Some common problems are as follows:
In debugging discussions, after exploring multiple potential solutions and error messages, the AI loses track of the original problem that started the conversation.
Technical discussions face particular challenges when topics shift and evolve. Starting with database design, moving to API architecture, and then circling back to database optimization often results in the AI having no recollection of the original database discussion.
Customer support conversations frequently loop back to questions already answered, with the AI asking for information that was provided at the beginning of the chat.
The reference breakdown becomes especially obvious when we use contextual phrases. Saying “the function we discussed” or “that approach” results in the AI asking for clarification, having lost all awareness of what was previously discussed.
Understanding why this happens is crucial for anyone using AI assistants in their daily work, building applications that incorporate these models, or simply trying to grasp the real capabilities and limitations of current AI technology.
In this article, we will try to understand why LLMs don’t actually remember anything in the traditional sense, what context windows are, and why they create hard limits on conversation length.
Context Windows: The Illusion of Memory
LLMs don’t have memory in any traditional sense.
When we send a message to ChatGPT or Claude, these models don’t recall our previous exchanges from some stored memory bank. Instead, they reread the entire conversation from the very beginning, processing every single message from scratch to generate a new response.
Think of it like reading a book where every time someone wants to write the next sentence, they must start again from page one and read everything up to that point. If the book has grown to 100 pages, they read all 100 pages before adding sentence 101.
This is a stateless approach where each request is independent. It might seem incredibly wasteful at first glance. However, the actual data transmission is surprisingly small. A lengthy 30,000-word conversation may translate to only about 200-300 kilobytes of data. For perspective, a single photo on a social media platform typically ranges from 1-2 megabytes, making it five to ten times larger than even an extensive AI conversation. Modern internet connections, even basic broadband, transfer this amount of data in fractions of a second.
The real bottleneck isn’t network transmission but computational processing. While sending 300KB takes milliseconds, processing those tokens through the model takes much longer
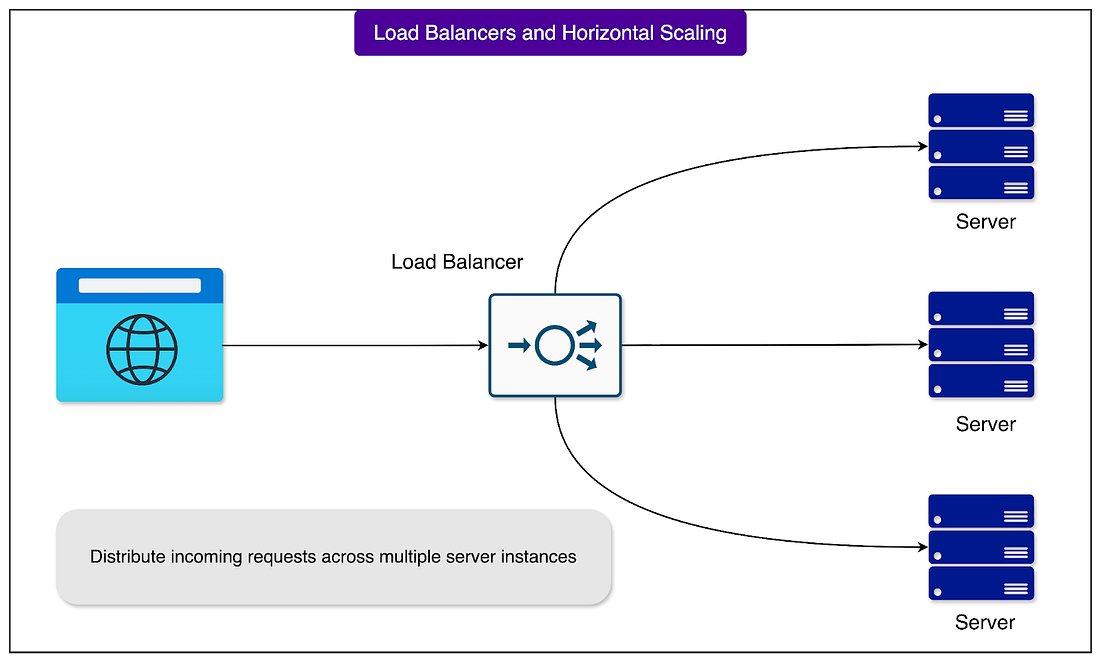
However, this stateless design enables crucial benefits. Any available server can handle any request without needing to coordinate with other servers or maintain session memory. If a server fails mid-conversation, another can seamlessly take over. This way, horizontal scaling with load balancing becomes easier.
 |
This stateless nature also means LLMs exist entirely in the present moment. There’s enhanced privacy since servers don’t store conversation state between messages. Once we close our browser, the conversation truly ends on the server side. When we close our browser tab and return an hour later, the LLM doesn’t remember our previous conversation unless we’re continuing the same session.
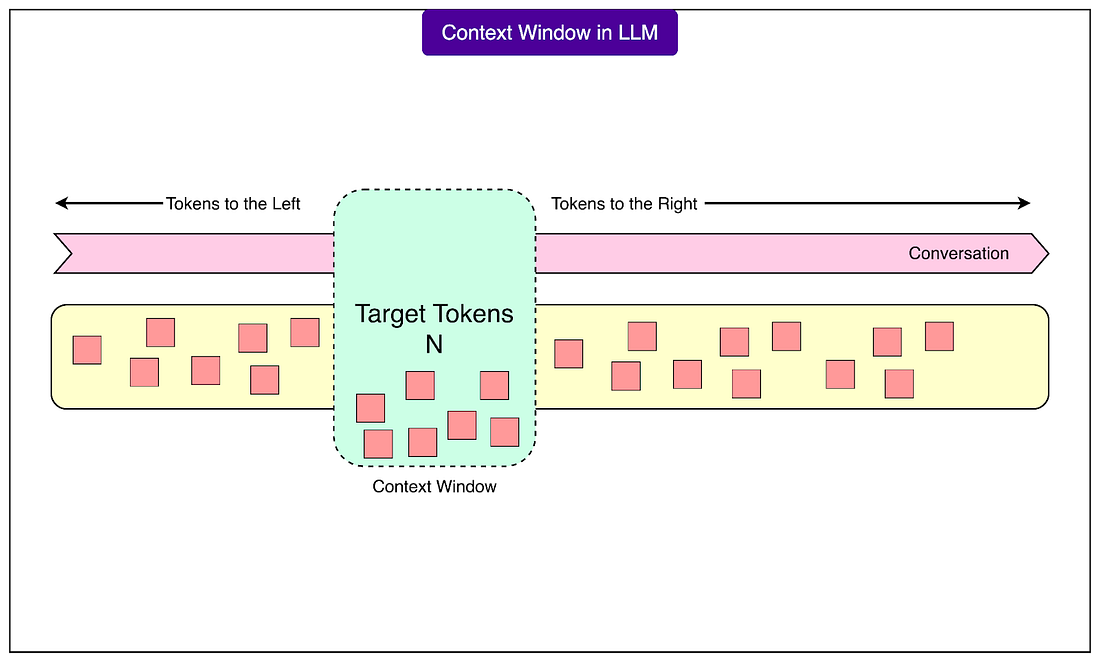
The rereading of the conversation happens within something called a context window, which functions like a fixed-size notepad where the entire conversation must fit. Every LLM has this notepad with a specific capacity, and once it fills up, the system must erase earlier content to continue writing. The capacity is measured in tokens, the fundamental units of text that LLMs process. A token is roughly three-quarters of a word, though complex technical terms, URLs, or code snippets consume many more tokens than simple words.
See the diagram below to understand the concept of context window:
 |
Modern context windows can vary dramatically in size:
Smaller models might have windows of 4,000 tokens, about 3,000 words, or a short story’s length.
Mid-range models offer 16,000 to 32,000 tokens, while the largest commercial models boast 100,000 to 200,000 tokens, theoretically capable of holding an entire novel.
However, these larger windows come with significant computational costs and slower processing times.
Everything counts against this token limit, including our messages, the AI’s responses, and hidden system instructions we never see. Before we even type our first word, the system has already used hundreds or sometimes thousands of tokens for instructions that tell the AI how to behave. Also, code snippets, URLs, and technical content consume tokens much faster than regular text. Even formatting choices like bullet points and line breaks have token costs.
When an LLM references something mentioned earlier or maintains consistent reasoning, it feels like memory. However, this illusion comes from the model processing all previous messages at that moment. In other words, it’s not