|
Generate your MCP server with Speakeasy (Sponsored)
 |
Like it or not, your API has a new user: AI agents. Make accessing your API services easy for them with an MCP (Model Context Protocol) server. Speakeasy uses your OpenAPI spec to generate an MCP server with tools for all your API operations to make building agentic workflows easy.
Once you've generated your server, use the Speakeasy platform to develop evals, prompts and custom toolsets to take your AI developer platform to the next level.
Disclaimer: The details in this post have been derived from the articles written by the Meta engineering team. All credit for the technical details goes to the Meta/Threads Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Threads, Meta’s newest social platform, launched on July 5, 2023, as a real-time, public conversation space.
Built in under five months by a small engineering team, the product received immediate momentum. Infrastructure teams had to respond immediately to the incredible demand.
When a new app hits 100 million signups in under a week, the instinct is to assume someone built a miracle backend overnight. That’s not what happened with Threads. There was no time to build new systems or bespoke scaling plans. The only option was to trust the machinery already in place.
And that machinery worked quite smoothly. As millions signed up in 5 days, the backend systems held on, and everything from the user’s perspective worked as intended.
Threads didn’t scale because it was lucky. It scaled because it inherited Meta’s hardened infrastructure: platforms shaped by a decade of lessons from Facebook, Instagram, and WhatsApp.
This article explores two of those platforms that played a key role in the successful launch of Threads:
ZippyDB, the distributed key-value store powering state and search.
Async, the serverless compute engine that offloads billions of background tasks.
Neither of these systems was built for Threads. But Threads wouldn’t have worked without them.
ZippyDB was already managing billions of reads and writes daily across distributed regions. Also, Async had been processing trillions of background jobs across more than 100,000 servers, quietly powering everything from feed generation to follow suggestions.
ZippyDB: Key-Value at Hyperscale
ZippyDB is Meta’s internal, distributed key-value store designed to offer strong consistency, high availability, and geographical resilience at massive scale.
At its core, it builds on RocksDB for storage, extends replication with Meta’s Data Shuttle (a Multi-Paxos-based protocol), and manages placement and failover through a system called Shard Manager.
Unlike purpose-built datastores tailored to single products, ZippyDB is a multi-tenant platform. Dozens of use cases (from metadata services to product feature state) share the same infrastructure. This design ensures higher hardware utilization, centralized observability, and predictable isolation across workloads.
The Architecture of ZippyDB
ZippyDB doesn’t treat deployment as a monolith. It’s split into deployment tiers: logical groups of compute and storage resources distributed across geographic regions.
Each tier serves one or more use cases and provides fault isolation, capacity management, and replication boundaries. The most commonly used is the wildcard tier, which acts as a multi-tenant default, balancing hardware utilization with operational simplicity. Dedicated tiers exist for use cases with strict isolation or latency constraints.
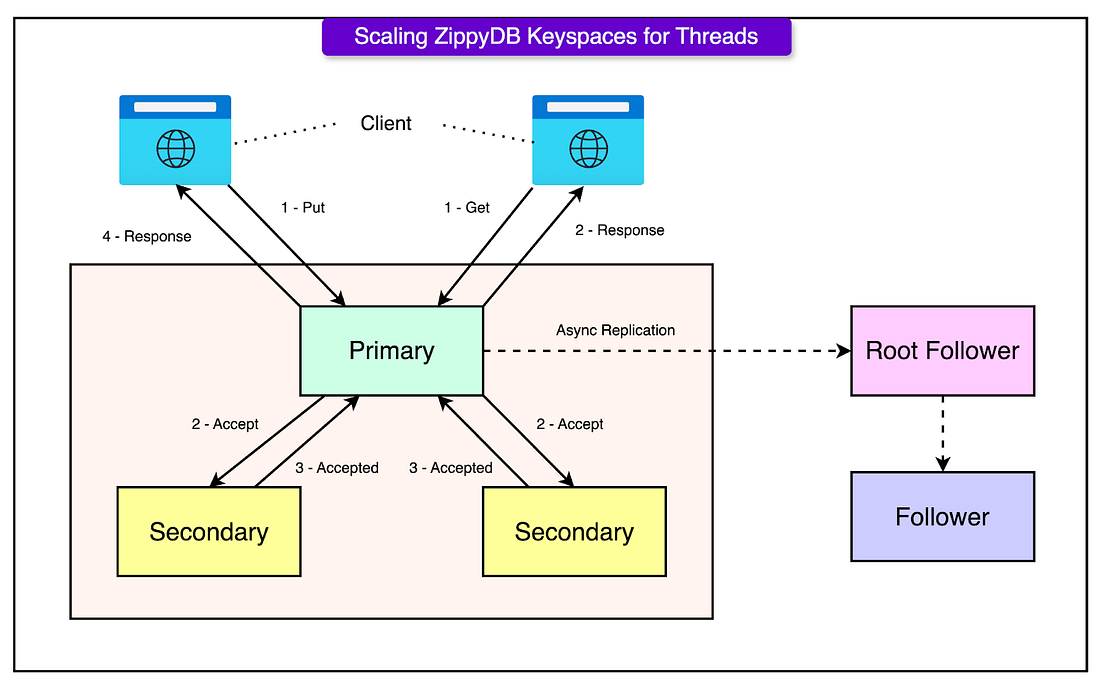 |
Within each tier, data is broken into shards, the fundamental unit of distribution and replication. Each shard is independently managed and:
Synchronously replicated across a quorum of Paxos nodes for durability and consistency. This guarantees that writes survive regional failures and meet strong consistency requirements.
Asynchronously replicated to follower replicas, which are often co-located with high-read traffic regions. These replicas serve low-latency reads with relaxed consistency, enabling fast access without sacrificing global durability.
This hybrid replication model (strong quorum-based writes paired with regional read optimization) gives ZippyDB flexibility across a spectrum of workloads.
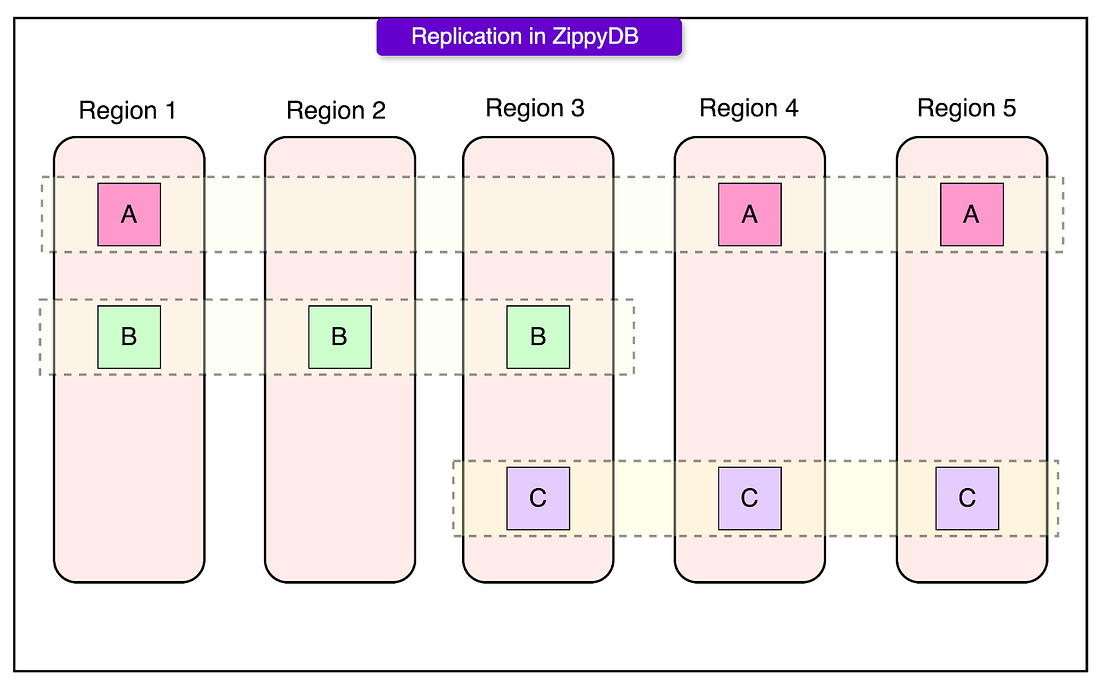
See the diagram below that shows the concept of region-based replication supported by ZippyDB.
 |
To push scalability even further, ZippyDB introduces a layer of logical partitioning beneath shards: μshards (micro-shards). These are small, related key ranges that provide finer-grained control over data locality and mobility.
Applications don’t deal directly with physical shards. Instead, they write to μshards, which ZippyDB dynamically maps to underlying storage based on access patterns and load balancing requirements.
ZippyDB supports two primary strategies for managing μshard-to-shard mapping:
Compact Mapping: Best for workloads with relatively static data distribution. Mappings change only when shards grow too large or too hot. This model prioritizes stability over agility and is common in systems with predictable access patterns.
Akkio Mapping: Designed for dynamic workloads. A system called Akkio continuously monitors access patterns and remaps μshards to optimize latency and load. This is particularly valuable for global products where user demand shifts across regions throughout the day. Akkio reduces data duplication while improving locality, making it ideal for scenarios like feed personalization, metadata-heavy workloads, or dynamic keyspaces.
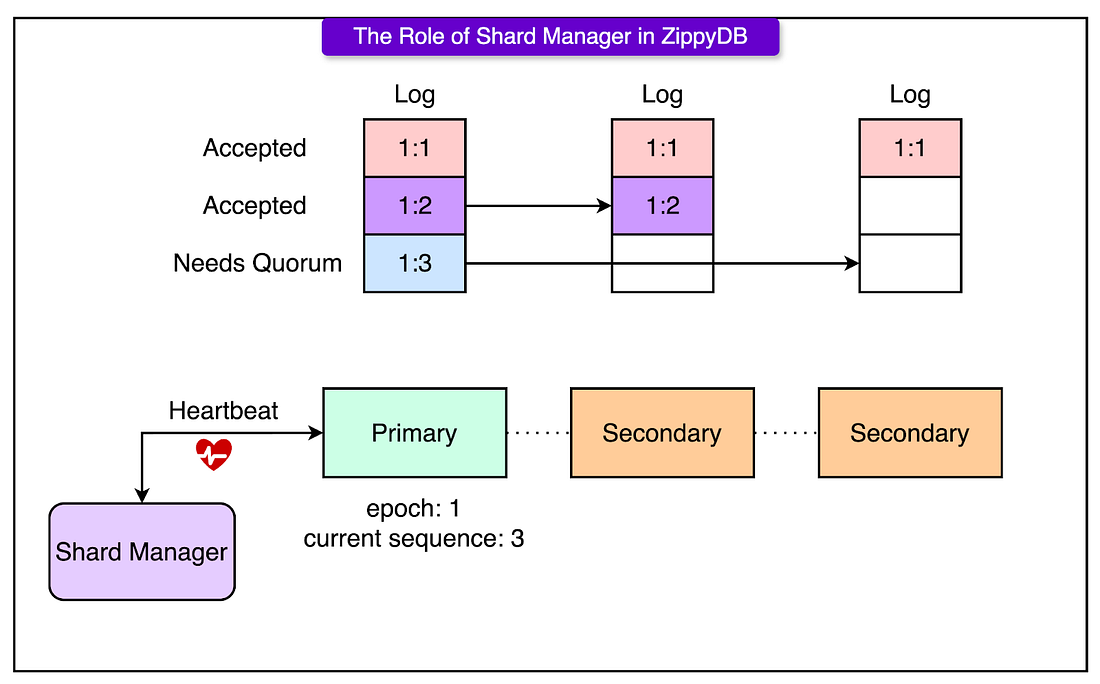
In ZippyDB, the Shard Manager acts as the external controller for leadership and failover. It doesn’t participate in the data path but plays a critical role in keeping the system coordinated.
The Shard Manager assigns a Primary replica to each shard and defines an epoch: a versioned leadership lease. The epoch ensures only one node has write authority at any given time. When the Primary changes (for example, due to failure), Shard Manager increments the epoch and assigns a new leader. The Primary sends regular heartbeats to the Shard Manager. If the heartbeats stop, the Shard Manager considers the Primary unhealthy and triggers a leader election by promoting a new node and bumping the epoch.
See the diagram below that shows the role of the Shard Manager:
 |
Consistency and Durability in ZippyDB
In distributed systems, consistency is rarely black-and-white. ZippyDB embraces this by giving clients per-request control over consistency and durability levels, allowing teams to tune system behavior based on workload characteristics.