|
The Robot Vacuum Making Intelligent Automation Possible at Home (Sponsored)
 |
Matic is the first visually intelligent robot vacuum that sees your home like you do, so it can clean how you want it to.
Matic’s hero features:
Runs entirely on cameras to deftly navigate obstacles
Recognizes floor types to auto-switch between vacuuming and mopping
Big wheels and a height-adjustable cleaning head handle thick rugs
Quieter than conversations at 55 dB
Handles pet hair without clogging or tangling
A single bag collects dry and wet waste—diaper-salts gel dirty water, antimicrobial powder prevents mold
A fresh HEPA filter in every bag for cleaner air, no washing or replacing
Experience autonomous cleaning with Matic with a 180-day money-back guarantee.
OpenAI runs voice AI for 900 million users a week, and they use WebRTC for it because the alternative would mean reinventing how the internet handles live audio.
The catch is that WebRTC was designed for servers with stable IPs and ports, and Kubernetes treats those addresses as disposable. The conventional answer at this scale is an SFU, which suits multiparty workloads like group video calls, but OpenAI’s traffic is overwhelmingly one user talking to one model.
To deal with this, their architecture splits the stack into two pieces:
A stateless relay handles protocol-aware packet routing at the geographic edge.
A stateful transceiver owns all the heavy WebRTC state.
The trick that ties them together is using the ICE ufrag, a field the protocol already exchanges during setup, as a routing key that the relay can read off the first packet of a new session. Everything else, from Global Relay to the userspace Go implementation to the Redis cache and the careful socket-level optimizations, builds on top of that core idea.
In this article, we will look at the entire journey in detail and challenges the OpenAI engineering team faced.
Disclaimer: This post is based on publicly shared details from the Open AI Engineering Team. Please comment if you notice any inaccuracies.
Why Latency Matters For Voice AI
Voice AI either feels like a conversation or it feels like a walkie-talkie. The line between those experiences is measured in milliseconds.
When the network pauses between hearing a user and responding, the illusion breaks. Pauses turn awkward, interruptions get clipped, and users are compelled to cut off the AI mid-sentence, which is also kind of rude. In other words, voice AI only feels natural if the conversation moves at the speed of speech.
The harder constraint underneath is the continuous-stream property. Audio has to arrive at the model as a steady flow, rather than as a single upload after the user finishes talking. That stream is what lets the model start transcribing, reasoning, and calling tools while the user is still speaking. The experience collapses into push-to-talk once it breaks.
For OpenAI specifically, those constraints translate into three concrete requirements:
The system has to reach 900 million weekly active users wherever they are.
Connection setup has to be completed quickly enough that users can start speaking as soon as a session begins.
Round-trip time for audio has to stay low and stable so turn-taking feels crisp.
WebRTC is the protocol the industry built for this kind of work. It is a bundle of smaller protocols (ICE for figuring out how two endpoints reach each other across firewalls, DTLS for encrypting the channel, SRTP for the audio packets, and RTCP for quality feedback). Justin Uberti, one of WebRTC’s original architects, and Sean DuBois, who maintains the Pion library OpenAI builds on, both work at OpenAI today. That kind of protocol depth shows up in the architecture they shipped.
The Original Architecture
The first version of OpenAI’s WebRTC infrastructure was a single Go service built on Pion. It handled both jobs in one place:
On the signaling side, the service negotiated SDP (the format clients and servers use to describe a session), selected codecs, generated ICE credentials, and set up sessions.
On the media side, the service terminated WebRTC connections from clients and maintained upstream connections to the backend services that run the AI models, including inference, transcription, speech generation, tool use, and orchestration.
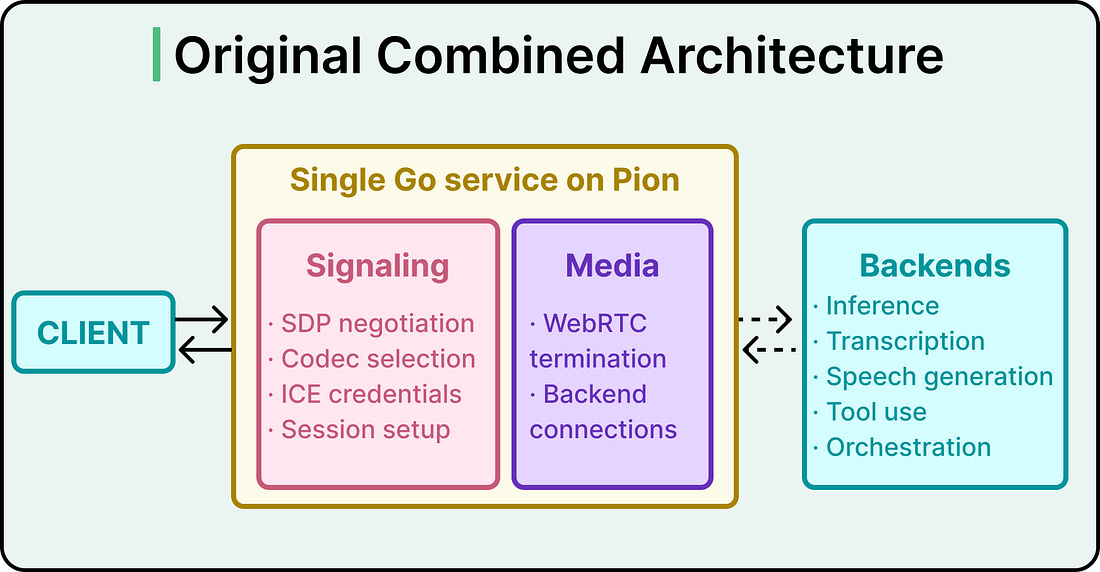 |
That combined service still powers ChatGPT voice, the Realtime API’s WebRTC endpoint, and several research projects, and it has handled that work well. The question OpenAI ran into was how to deploy it on Kubernetes, the container orchestration system that runs most modern cloud infrastructure.
Kubernetes assumes compute is cheap and movable. Pods come up, get scheduled wherever capacity exists, run for a while, then get rescheduled or replaced. Standard WebRTC deployment patterns assume the opposite. That mismatch shows up in two specific places.
The first is port exhaustion.
The conventional way to deploy WebRTC uses one UDP port per session. At OpenAI’s scale, that means tens of thousands of