|
Add auth to your app from the terminal (Sponsored)
 |
Run npx workos@latest and an AI agent will inspect your project, detect your framework, and add AuthKit directly to your codebase.
This is not a generic starter template. The agent reads your actual app, writes the integration where it belongs, then typechecks and builds so it can fix errors along the way. AuthKit gives you hosted auth, customizable UI, MFA, social login, session management, and a path to enterprise features like SSO and SCIM when you need them.
Free up to 1 million MAUs.
What feels like a real-time conversation with AI today is built from many parts working together.
At the center sits a language model that works in turns, the same way ChatGPT does when you type to it. The responsiveness comes from a layer of helper systems wrapped around that model, predicting when the user has paused, transcribing audio, generating speech from text, and weaving the pieces together fast enough that the conversation feels fluid.
However, new research from Thinking Machines argues that this whole approach has a ceiling, and proposes a different way to build AI systems for real-time interaction.
Thinking Machines is a relatively new AI research lab focused on human-AI collaboration, publishing research under the name Connectionism and offering developer-facing products for the broader community. What sets them apart is the problem they have identified as central. Most AI labs treat autonomous capability as the most important capability to push forward, meaning the ability for a model to take a task, do the work on its own, and return a result.
Thinking Machines argues this framing sidelines humans. Real work, in their view, benefits from continuous collaboration where the human clarifies, redirects, and gives feedback as the model goes along. The interface should support that, rather than treating the human as someone who hands off a task and walks away.
In this article, we will look at what the research preview covers and the concept of an interaction model proposed by Thinking Machines.
Disclaimer: This post is based on publicly shared details from the Thinking Machines Engineering Team. Please comment if you notice any inaccuracies.
Bottleneck
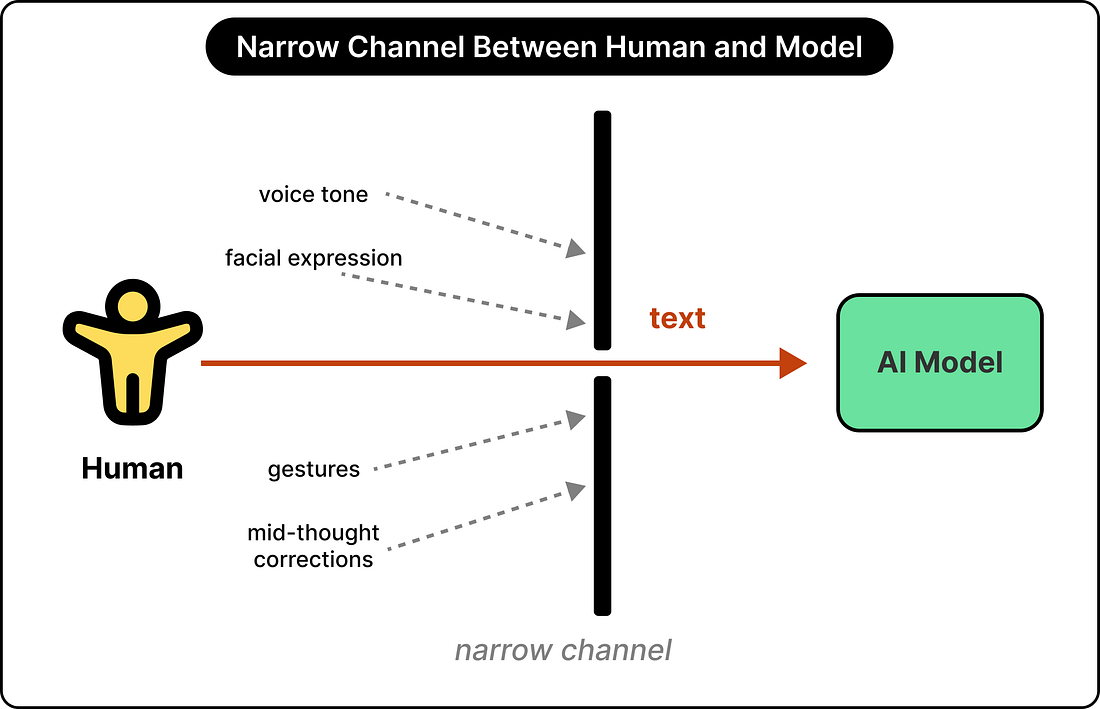
The problem starts with how today’s models actually experience the world. A typical language model works in a single thread. It waits for the user to finish typing or speaking before it can perceive any input. Once the model starts generating a response, its perception freezes, and any new input gets queued for later.
Thinking Machines compares this setup to resolving a crucial disagreement over email rather than in person. The bandwidth is just too narrow. So much of what makes a collaboration work, the way your voice shifts when uncertain, the moment of realizing a direction change is needed mid-sentence, the reaction on your face when the other person says something useful, all of it gets stripped out of the channel between human and model.
This matters because real work that benefits from another mind in the room depends on that bandwidth.
A model that only sees clean, finalized inputs forces a person to think like a model, preparing the full request, handing it over, and then waiting. In contrast, real collaboration is often messy, interruptive, and full of mid-stream corrections. Until the interface allows for that, the human ends up doing extra work to fit how the model wants to operate. Thinking Machines argues this bottleneck explains why much of today’s AI work feels like prompting and waiting rather than collaborating the way two people might.
 |
Harness
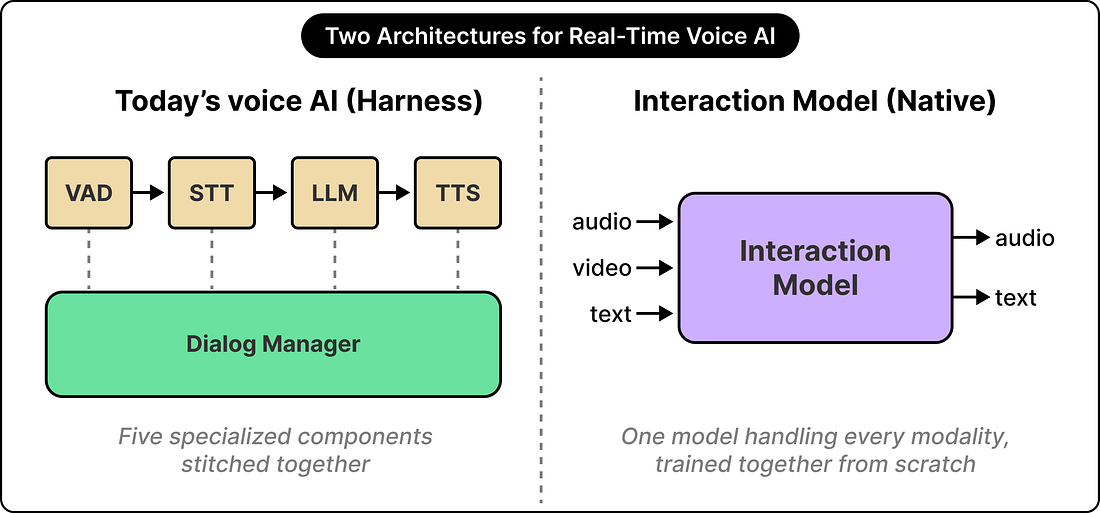
If today’s voice AI feels real-time despite this limitation, how is that even working to a large extent? The answer is a pattern called a harness.
A typical voice AI product is a stack of components glued together:
Voice activity detection listens for pauses and decides when the user has stopped speaking.
A speech-to-text model transcribes what was said.
A language model generates a text response.
A text-to-speech model converts that response back into audio.
A dialog manager orchestrates the entire pipeline so the latency feels acceptable.
Imagine a brilliant scholar who communicates only through letters slipped under a door. Making this feel like a conversation requires helpers. One stands outside listening for when the visitor stops talking, another reads the scholar’s letters aloud when they come back, and a third rings a bell when something visible happens that the scholar should know about.
The setup mostly works, but the scholar still experiences reality through letters. Voice tones, facial expressions, the moment itself, all of it stays beyond the scholar’s reach. This is what every real-time voice AI actually is, with a turn-based language model at the center surrounded by helpers that simulate conversation around it.
 |