|
Who’s actually reviewing all that AI-generated code? (Sponsored)
 |
When devs use AI to generate thousands of lines of unverified code, you risk a codebase slopocalypse. The review step becomes your team’s bottleneck, and the last thing standing between a subtle bug and production.
Greptile reviews each PR with full repo context and learns your team’s conventions over time from comments, reactions, and what gets merged. It flags real issues and suggests fixes that match your team, not generic best practices.
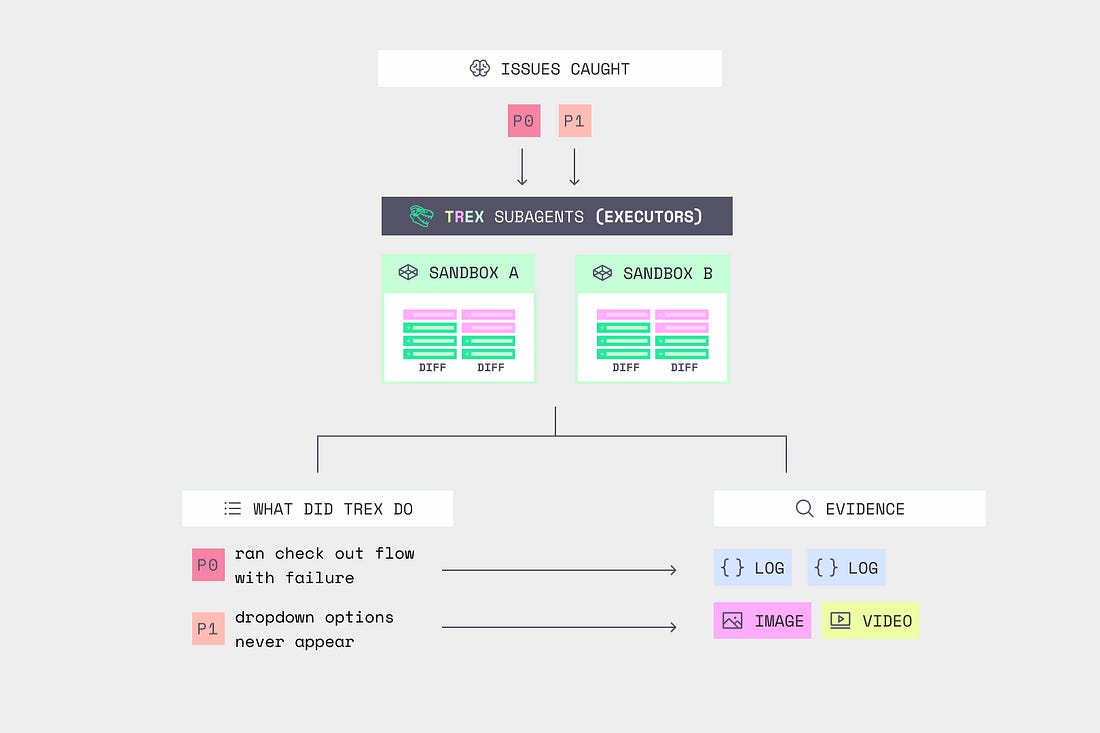
✅ Recently launched TREX runs your code, not just reads it. Greptile executes the change in a sandbox and returns screenshots, logs, and traces as proof of what actually broke.
✅ Review from your terminal. The Greptile CLI runs the same review locally, before you ever open a PR.
✅ Trusted by engineering teams at NVIDIA, Scale AI, and Brex.
✅ Now integrated with Claude Code: install via /plugin.
✅ Free for open source.
Even the most sophisticated AI agent in your stack starts every single message from a blank slate.
The model itself sees only the text placed in front of it at that exact moment, and the rest of the conversation lives outside its awareness entirely. Whatever continuity we feel when chatting with Claude or ChatGPT is something the surrounding platform is engineering on the model’s behalf, by inserting the right context back into every call. Once we understand this crucial distinction, the entire field of agent memory becomes a very different engineering problem from what it first appears to be.
In this article, we will try to understand how that architecture gets built, from the constraint that forces it to exist all the way to the tradeoffs that follow.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
Statelessness
A call to a large language model follows a simple pattern. The system sends a prompt, the model returns a response, and the exchange concludes there. Each subsequent call, even one made a millisecond later, begins from a completely fresh slate. This is the API contract for every commercial LLM and reflects how transformers serve traffic.
See the diagram below:
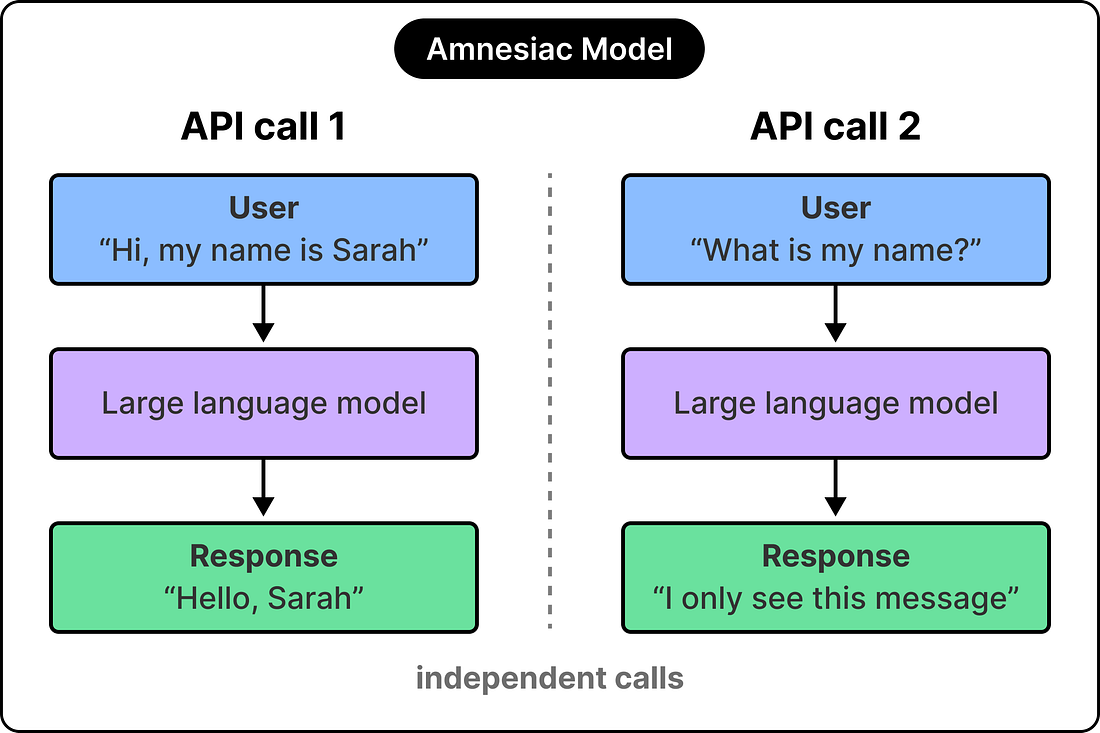 |
When we say things like “Claude remembers our conversation from yesterday,” we are describing a property of the product rather than a property of the actual model itself. The platform writes things down on the model’s behalf, then reads them back into the prompt at exactly the right moment, so the model can reason as if it had been there all along. The intelligence resides within the model itself, while the memory resides in the system surrounding it.
If the model itself works this way, the next question is whether we can solve the memory problem by writing everything into the model’s view on every call? The way this approach breaks gives us a better insight into how to solve this problem.
Context
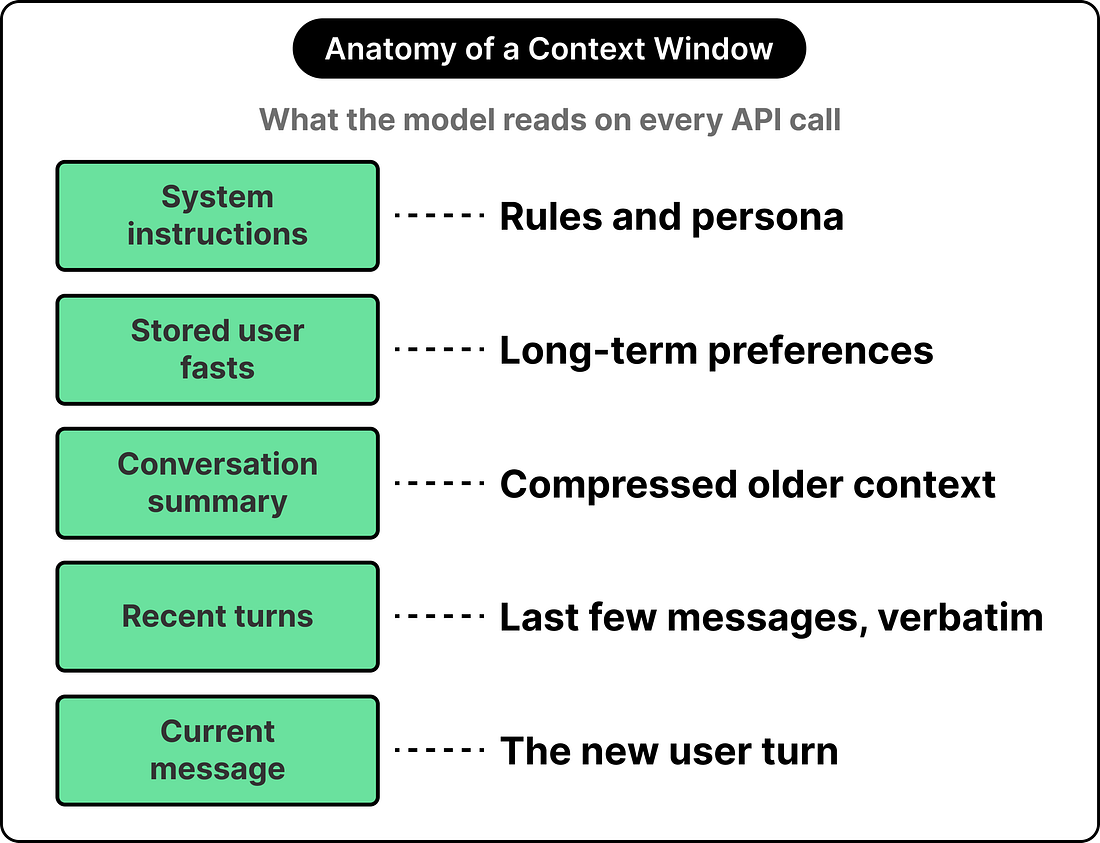
Every API call has a context window. It is basically the bounded slab of text that the model reads when generating its response. This includes the system prompt, the user’s current message, and anything else the developer has placed there. The model has full visibility into the contents of the window, while whatever sits outside it might as well live on a different machine.
See the diagram below:
 |
An obvious approach to memory involves writing the entire conversation history into the context window on every call. This works well for the first few turns of a chat. Once the conversation grows longer, however, three significant problems emerge at once:
The first problem is cost. Every token in the context window is paid for on each call, in both money and latency, so a linearly growing conversation produces a linearly growing bill. By message eighty, the system might be re-sending tens of thousands of tokens on every turn just to maintain continuity.
The second problem is latency. Larger contexts take longer to process, and a model that responds in two seconds on a short prompt may take ten or fifteen on one that has filled most of its window.
The third problem is the most counterintuitive of the three. The model’s attention degrades inside long contexts, and information placed in the middle of a long prompt is recalled less reliably than information at the beginning or the end. Researchers refer to this as the lost-in-the-middle effect.