|
How Amex Designs for Low-Latency Failure Isolation
A deep dive into American Express’ cell-based payments architecture, how it reduces blast radius, supports failover, keeps latency predictable, and what platform teams can learn from
Free Claude Code Course with Lydia Hallie, Anthropic (Sponsor)
 |
We partnered with Anthropic to make our Claude Code course free for everyone. No subscription, no trial. Just dive in.
It’s taught by Lydia Hallie, who’s been an instructor with us for years and now works on the Claude Code team at Anthropic. When she taught Claude Code live, it broke every platform record we have with over 10,000 people tuning in.
Lydia has a knack for visualizing how tools work under the hood, which is exactly the mental model you need to stop guessing with AI and start directing it.
Payment systems live in one of the least forgiving areas of distributed systems engineering. A delayed transaction is not just a slow API call. It can become an abandoned cart, a stranded customer, a failed merchant sale, a fraud review problem, or a reconciliation issue downstream.
That is why the American Express engineering article on cell-based architecture is important. It is not simply another cloud-native modernization story. It is a case study in how one of the world’s major payments ecosystems thinks about failure before failure happens.
The core idea is simple but powerful: do not build one giant platform where every service, database, configuration dependency, and routing path can become part of the same failure domain. Instead, divide the platform into independent cells. Each cell has the services, databases, DNS, observability, and supporting infrastructure needed to process transactions locally. If one cell fails, the failure stays inside that cell. Other cells continue processing.
That sounds obvious until you apply it to payments, where strong consistency, duplicate prevention, partner routing, issuer communication, fraud checks, merchant rules, currency data, and compliance constraints all collide in the same transaction path.
The real lesson from Amex’s architecture is this: in mission-critical payments, resiliency is not achieved by adding retries after the fact. Resiliency is achieved by making failure boundaries a first-class architectural primitive.
What Cell-Based Architecture Means in Payments
A cell is an isolated, independently deployable unit of the system. It contains the microservices, databases, local routing, local observability, and supporting services needed to process a subset of transactions.
In a traditional distributed system, services may be split into microservices but still share central databases, global caches, global configuration services, centralized observability pipelines, and cross-region synchronous dependencies. That can look distributed on a diagram while still behaving like a tightly coupled system during failure.
Cell-based architecture goes further. It asks a stricter question:
Can this part of the platform continue operating if another cell, region, database cluster, logging system, or downstream dependency is degraded?
In the Amex design, each cell is a failure domain. It does not span multiple regions. It has local services and local databases. It does not depend on synchronous cross-cell calls during transaction processing. The Global Transaction Router, or GTR, decides where transactions should go and enforces the boundaries between cells.
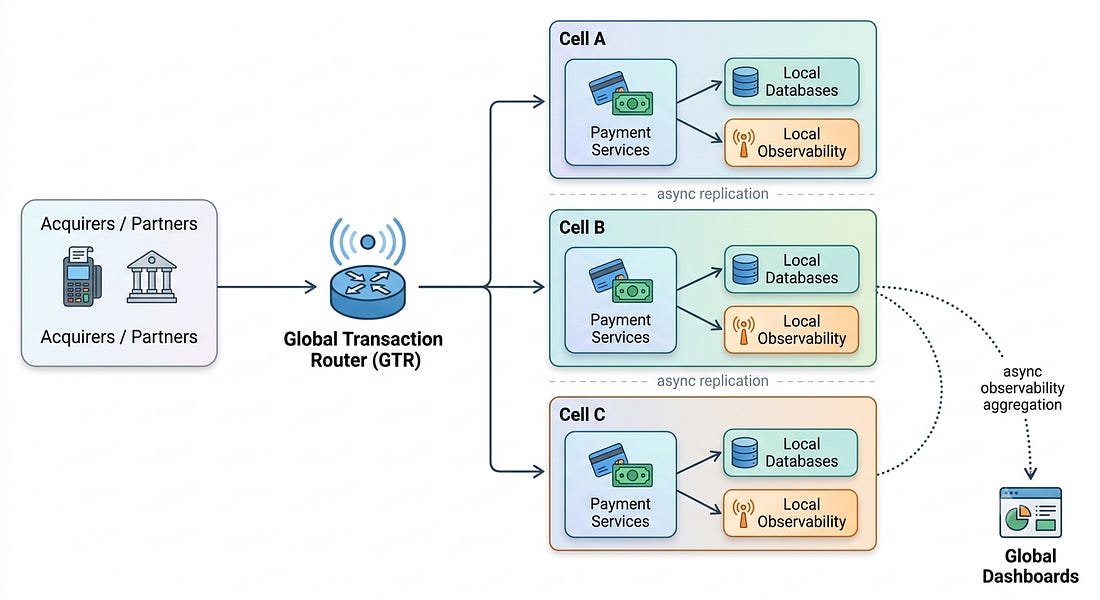 |
The important detail is not that there are multiple boxes. The important detail is that the boxes do not depend on one another synchronously in the critical path.
That is the difference between a distributed system and a resilient distributed system.
Payment Failures Are Business Failures
In most consumer software, a degraded experience may mean a page loads slowly or a user refreshes. In payments, the consequences are immediate.
A card authorization flow has to answer a business-critical question in milliseconds: should this transaction be approved, declined, routed, retried, enriched, or stopped?
The platform must handle high-volume traffic, unpredictable demand spikes, partner-specific routing, fraud checks, issuer connectivity, currency rules, merchant category data, settlement implications, and retry behavior. It must do all of this while keeping latency predictable.
Real payment outages show how fragile the ecosystem can become when a central dependency fails.
In 2018, Visa experienced a major service disruption in Europe caused by the failure of a switch in one of its data centers. Visa later told the UK Parliament that 91% of UK cardholder transactions processed normally during the incident, but 9% failed on the first attempt, with peak disruption periods where average failure rates reached 35%. That is a powerful example of why blast-radius reduction matters. A single infrastructure fault can become visible to merchants and consumers across countries.
Square’s 2023 outage offers another lesson. Square said the incident was caused by DNS servers, and noted that without DNS, Square products, internal tools, and services could not communicate. In 2025, Square and Cash App also reported a system-wide disruption tied to a security certificate validation problem that temporarily prevented payment systems from communicating properly with databases.
These are not exotic failures. They are the ordinary enemies of distributed systems: DNS, certificates, routing, configuration, data-center networking, overloaded dependencies, and retries. Cell-based architecture is a way of designing so that ordinary failures do not become total platform failures.
Principle 1: Reduce Blast Radius Before You Optimize Everything Else
The primary benefit of cell-based architecture is reducing blast radius. If one cell fails, only the traffic assigned to that cell should be affected. The rest of the platform should continue operating.
This is similar to the bulkhead principle in ships: divide the ship into watertight compartments so that damage in one section does not sink the entire vessel.
In payments architecture, blast radius can be defined across several dimensions:
percentage of total transactions affec