|
Code review needed a new architecture. We open-sourced it. (Sponsored)
 |
Code review broke when AI started writing the code.
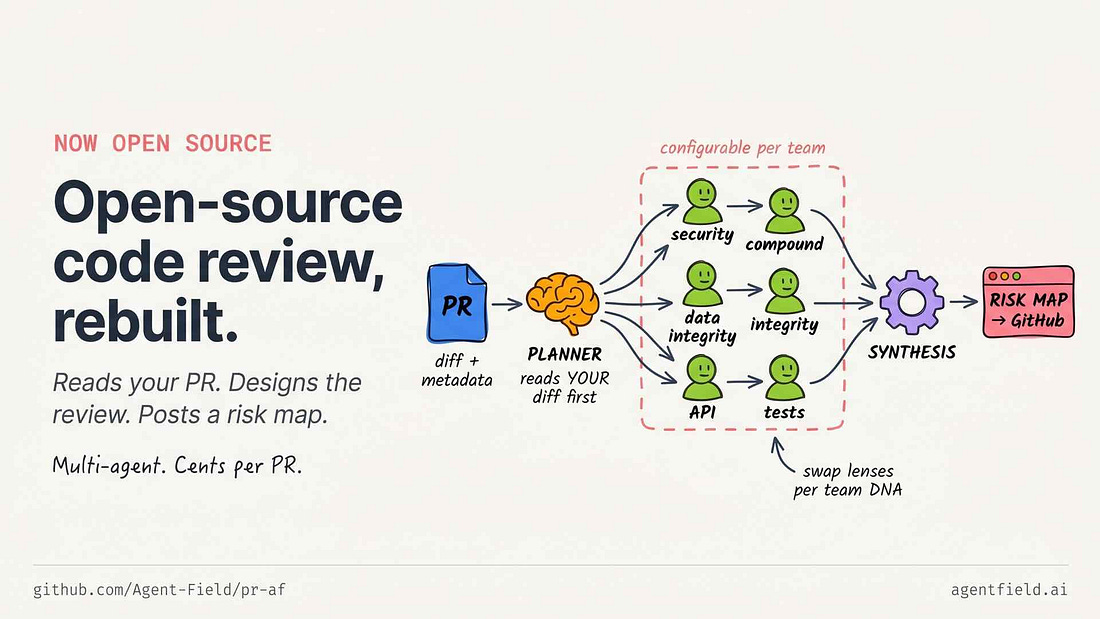
AgentField just shipped a multi-agent code reviewer with dynamic meta-orchestration. The planner reads each PR first, then compiles a custom review strategy for it - security agents for auth changes, schema agents for migrations, behavioral agents for refactors. Configurable per team. Deploy it with one docker compose. Runs on open or closed models (Kimi, DeepSeek, Claude). Costs cents per review on open models - no per-seat licenses.
AgentField’s writeup: the four jobs of code review, which three stay load-bearing once AI writes the first draft, and why static pipelines fail.
LLM agents can burn millions of tokens on a single task. They put a model in a loop, resend the full context every step, and usually call the most expensive one available. Costs scale fast.
To understand how teams keep this under control in production, we sat down with Scott Breitenother and Sid Sijbrandij, co-founders of Kilo, an open-source coding agent that runs through a lot of these loops every day. The patterns they shared are not specific to coding, and most of them are not unique to Kilo either. Similar approaches show up in tools like Cursor, Cline, and Aider, and in shared infrastructure like OpenRouter and RouteLLM. If you build any agent that makes many model calls, the same ideas apply.
Why Running an LLM Agent Gets Expensive
A single request to a language model is usually cheap. An agent built on the same model is not. The difference is that an agent makes many calls instead of one, and it tends to send them to the most expensive models available. Both of these drive the cost up.
1. Frontier Models Cost a Lot Per Token
The most capable models are called frontier models. They sit at the leading edge of what is possible, and they cost the most per token. Below them is a range of cheaper models that give up some capability for a lower price, down to small models that are very cheap and still handle simple work well.
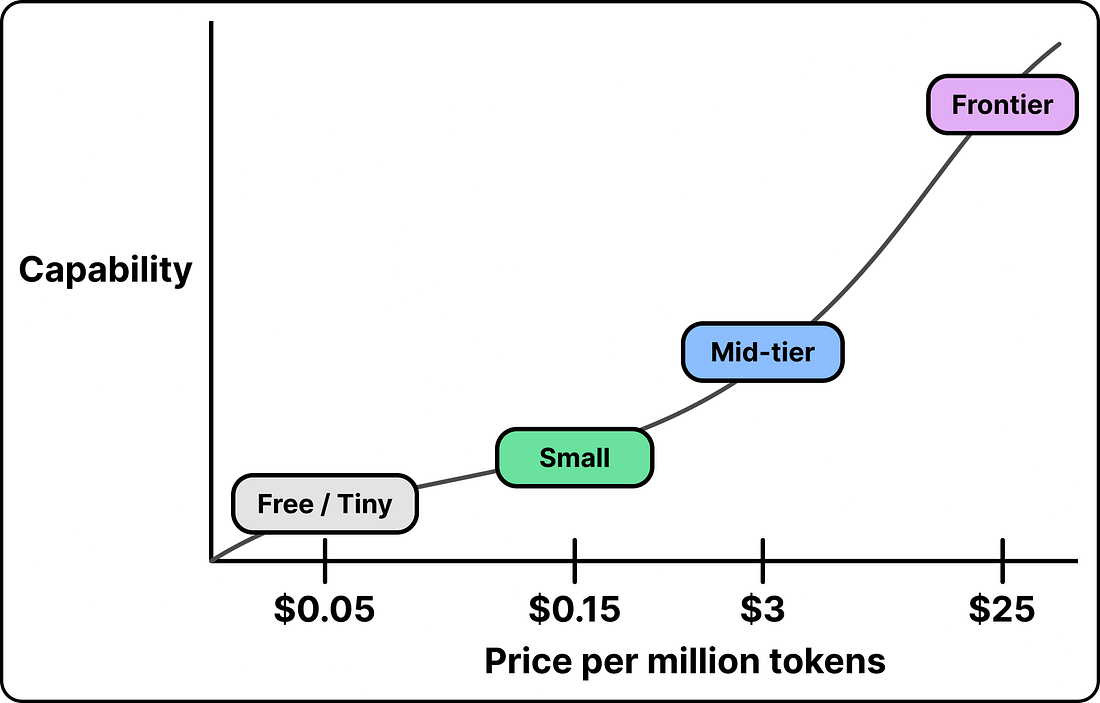 |
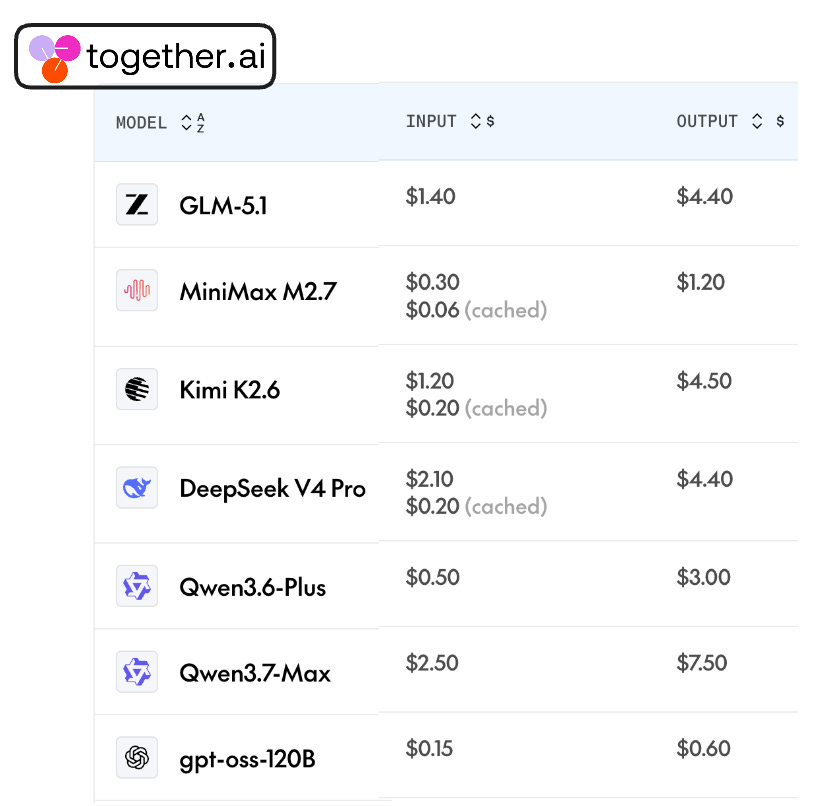
The gap across that ladder is large. The top model often costs more than ten times what a small one costs for the same work. Teams that use frontier models to power their applications pay frontier prices for everything, which makes the whole system expensive.
 |
2. The Agent Loop Multiplies Every Call
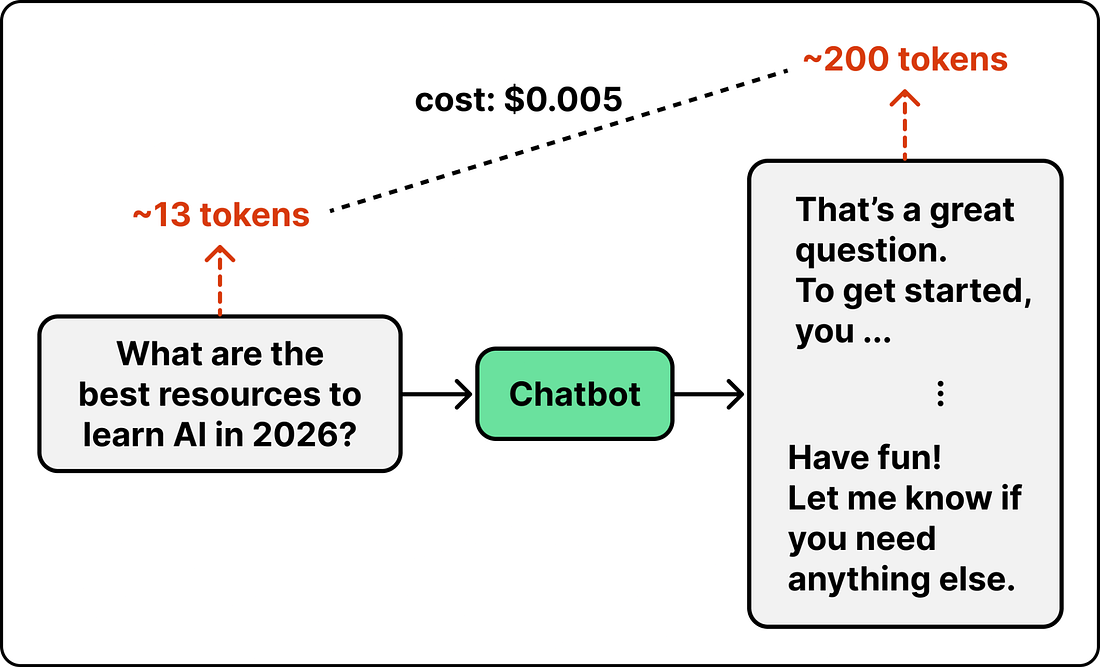
Frontier models are expensive per token, but in a standard chatbot setting, the cost is manageable. For example, Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens. A single question and answer is only a few thousand tokens, so it costs under two cents. At that rate, you can ask a lot of questions before the cost matters.
 |
LLM agents are different. They do not produce an answer immediately. They run in a loop. The agent reads the task, takes an action like running a tool or reading a file, looks at the result, and decides what to do next. To see why this gets expensive, look at what each step sends to the LLM.