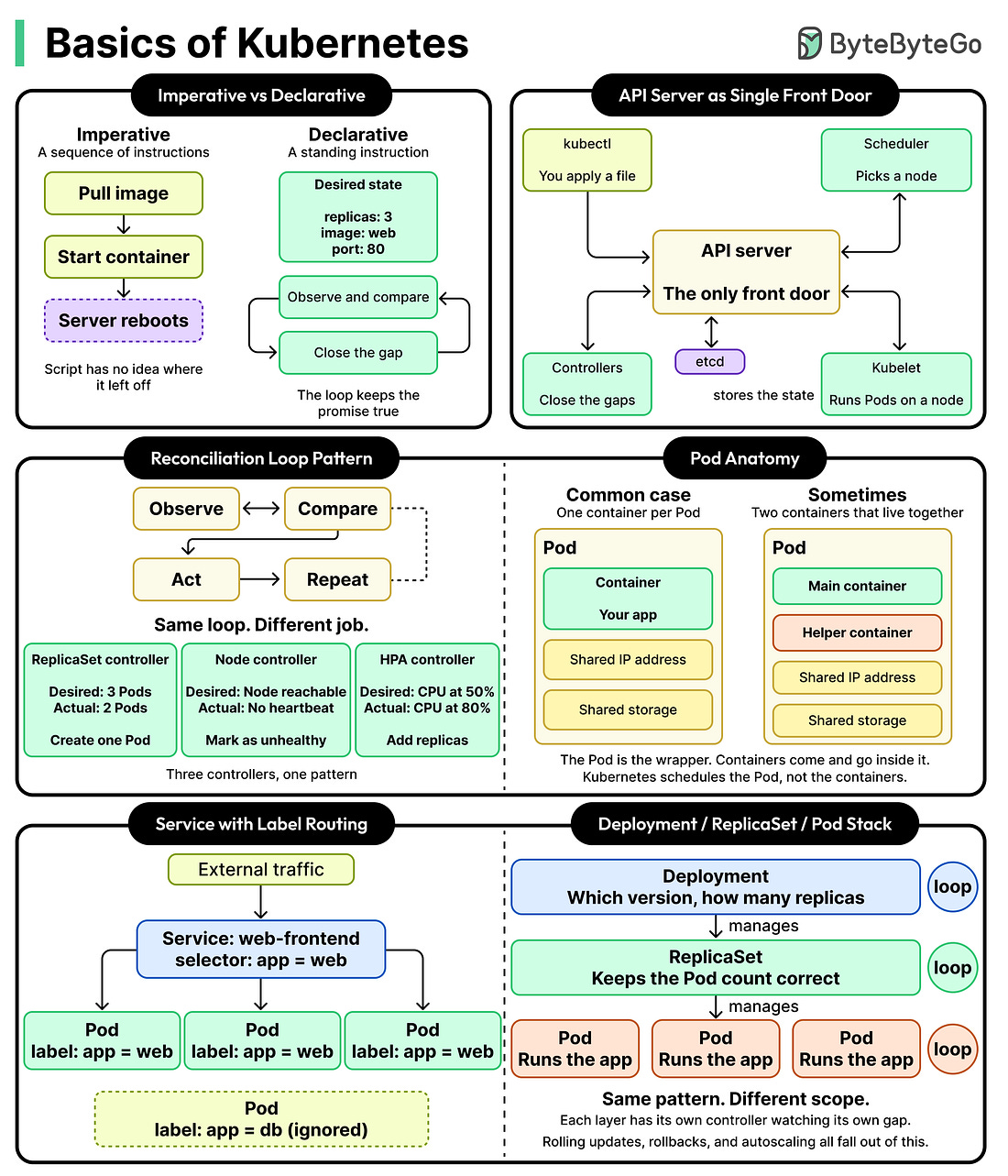
|
Latest articles
If you’re not a subscriber, here’s what you missed this month.
 |
To receive all the full articles and support ByteByteGo, consider subscribing:
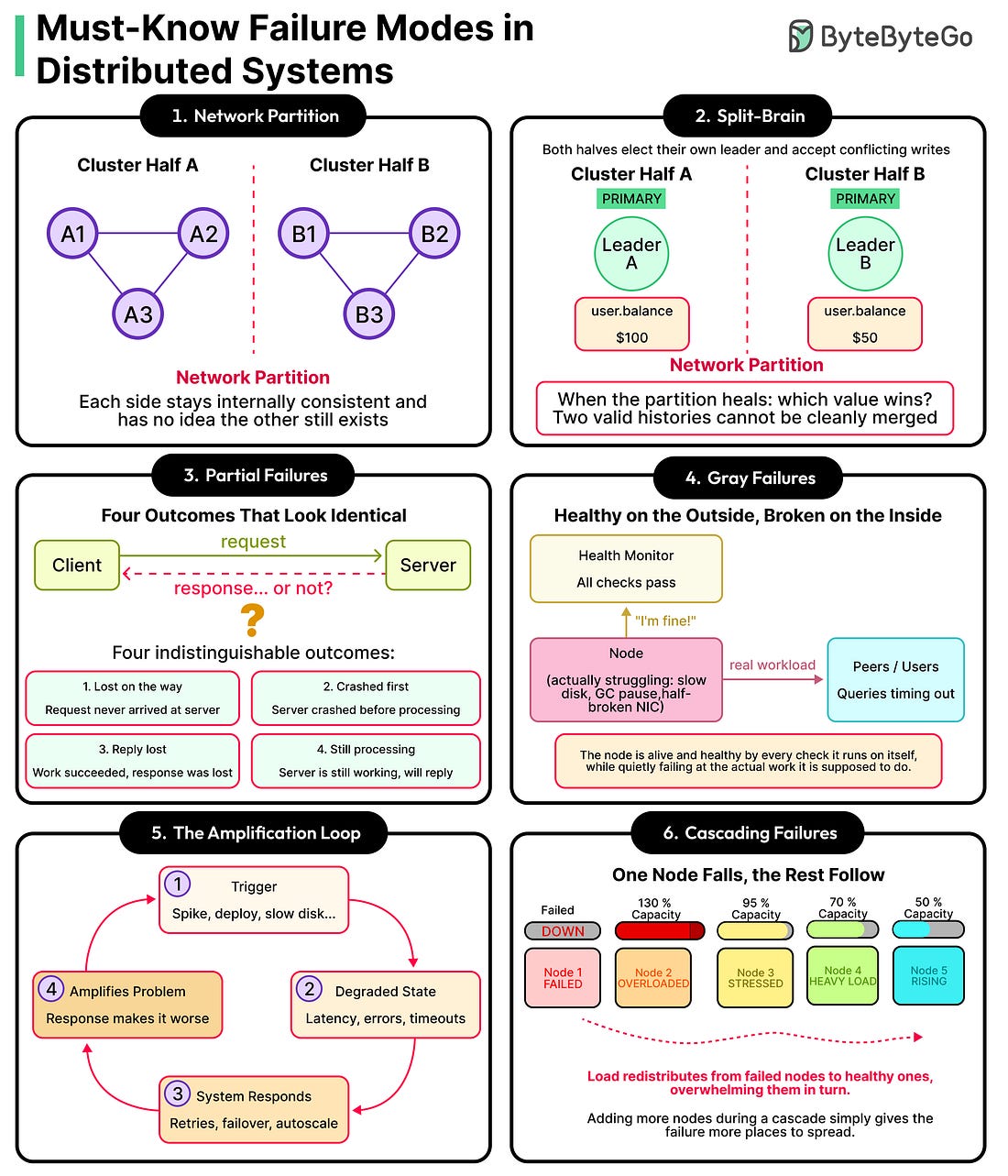
What does it mean for a distributed system to be up?
On a single machine, the answer is straightforward, since a program is either running or it has crashed, and the line between the two is usually obvious from a stack trace.
Distributed systems are not so simple. Every server can report healthy while users are seeing errors, the whole system can be technically working but stuck in a state it cannot recover from on its own, and it can quietly serve wrong data while every dashboard glows green.
None of these may be because of bugs in the conventional sense. They are recurring failure patterns that have been showing up across systems for decades, with names, mechanisms, and standard ways of defending against them.
In this article, we will look at the most significant failure mode patterns in distributed systems and the standard approaches to deal with each of them.
 |
