|
Models are no longer the bottleneck. Agent context is. (Sponsored)
 |
Most AI agents don’t fail because of the model. They fail because the context is broken—stale data, fragmented systems, slow retrieval.
Join Simba Khadder, Head of AI Product & Director of Software Engineering at Redis, on June 10 to see how to turn scattered enterprise data into live, agent-ready context with Redis Iris.
You’ll learn:
The four failure modes of how context breaks in production
How to make your enterprise data navigable for runtime
How Redis Context Retriever, Search, Data Integration, and Agent Memory work together
The CockroachDB team wanted to add vector search to their distributed database, and dozens of well-known algorithms already existed.
To facilitate the decision-making process, they wrote down a list of architectural requirements, including a refusal to depend on any central coordinator, a refusal to allocate large in-memory caches, a need for real-time updates, an intolerance for hot spots, and a requirement to support sharding. Then they checked the list against the popular options.
Most failed at least one requirement, and some failed several. The team’s response was to build something new, called C-SPANN, that satisfied every constraint by treating the index as ordinary table data inside CockroachDB rather than as a separate system.
In this article, we will look at how the CockroachDB engineering team built this index and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the CockroachDB Engineering Team. Please comment if you notice any inaccuracies.
Vectors and Approximate Nearest Neighbor Search
A vector is a long list of numbers that captures the meaning of something.
Modern neural networks like the ones behind ChatGPT can take an image, a document, or a snippet of audio and convert it into a vector of floating-point numbers, typically a few hundred to a few thousand dimensions long.
The useful property of these vectors, often called embeddings, is that similar things produce similar vectors. For example, two photos of beaches end up close to each other in this multi-dimensional space, and a photo of a beach and the word “beach” end up in roughly the same neighborhood, which is what makes semantic search possible.
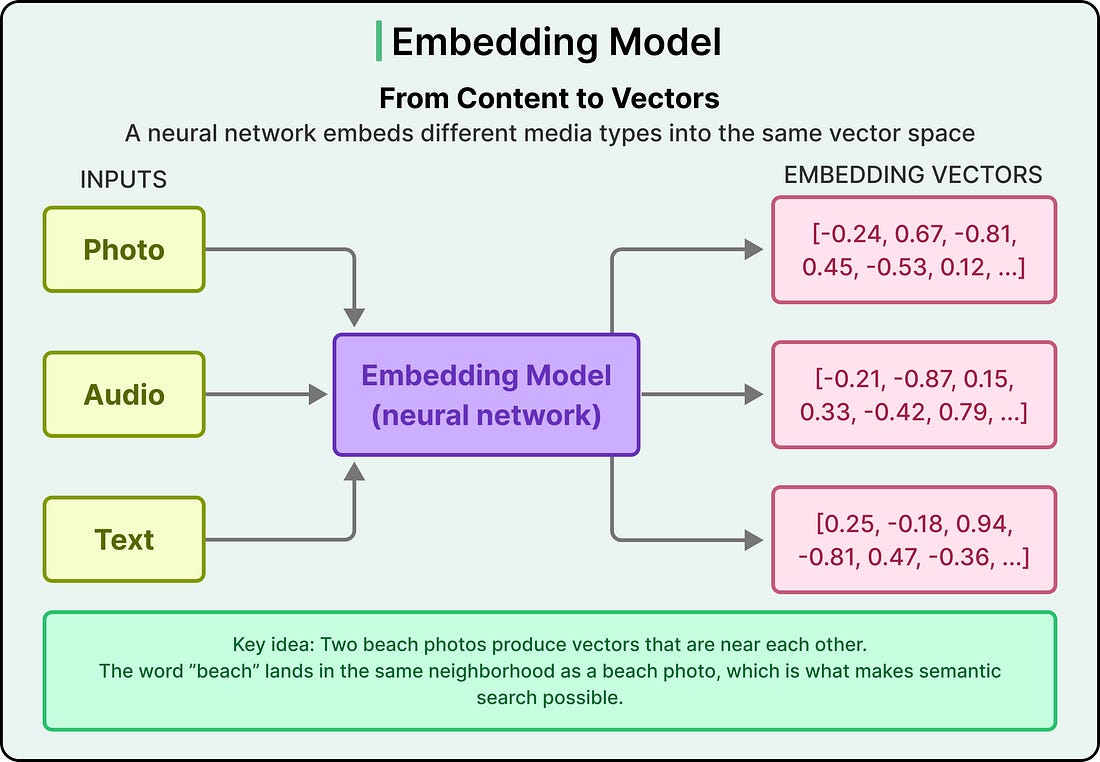 |
The trick is finding those neighbors quickly when you have billions of vectors to search through.
Traditional database indexes work because numbers and strings have a natural ordering. We can sort them, store them in a B-tree, and walk that tree to find what you want.
Vectors do not have that property. Should beach photos come before or after food photos? What about photos of food at the beach? There is no answer, because the data has no inherent sequence, which means a B-tree cannot help you.
The brute-force alternative is to compare your query vector against every stored vector and return the closest matches. This works fine for a few thousand vectors, but falls apart somewhere in the tens of thousands, and becomes hopeless once you reach the millions.
Vector indexes solve this by giving up on exact answers. They find approximate nearest neighbors, accepting a small loss of accuracy in exchange for orders of magnitude better performance. The results are usually close enough that real users cannot tell the difference, and the search runs fast enough to feel instant. That tradeoff between accuracy and speed is the foundation of every vector index, and the interesting engineering question is how you make the rest of the system work around it.
Even with a good algorithm for finding nearest neighbors, plugging it into a distributed transactional database is its own problem. That is where the CockroachDB story actually begins.
Architectural Constraints in a Distributed SQL Database
CockroachDB is a distributed SQL database. This means that the data lives across multiple machines, often across regions, and the system is designed to scale linearly. It guarantees transactional consistency and supports real-time updates, and all of this has to keep working when machines die, disks fail, or networks partition.
These properties impose a set of architectural constraints on any new feature, and a vector index is no exception. The CockroachDB team wrote down six requirements that any candidate algorithm had to satisfy.
The first requirement is that no single node can act as a central coordinator. Any node in the cluster should be able to serve reads and writes, because relying on a single leader to direct traffic creates a bottleneck and a single point of failure.
The second requirement is that the index cannot rely on large in-memory structures. Index state has to live in persistent storage, since the team could not assume every node has gigabytes of RAM available for caching vectors. They also wanted to avoid the long warm-up times that come with rebuilding in-memory caches after a restart, which matters especially for serverless deployments where nodes spin up and down on demand.
The third requirement is that network hops have to stay minimal. Round-trips between nodes are expensive, and any algorithm that requires sequential traversal across the cluster will accumulate latency unpredictably.
The fourth requirement is that the index data layout has to be sharding-compatible. Index data has to map naturally to CockroachDB’s key-value storage so that it can be split, merged, and rebalanced like any other table.
The fifth requirement is that the index must avoid creating hot spots. As inserts and queries scale up, the load has to spread across the cluster, because concentrating traffic on a single node defeats the point of running a distributed system in the first place.
The sixth requirement is that the index has to support incremental updates. Inserts and deletes need to be applied in real time without blocking queries, requiring batch rebuilds, or degrading search quality over time.
This list rules out the most popular vector indexes.
HNSW, the graph-based algorithm that powers pgvector, Weaviate, and many other systems, is excellent on accuracy benchmarks but builds its graph in memory and resists sharding. Classic IVF is closer in spirit