|
Build Durable Agents With Open Source Frameworks (Sponsored)
 |
Most AI agents work in demos — but fail in production. Learn how to build durable, enterprise-ready AI agents with open-source frameworks using Orkes Agentspan and Conductor. This whitepaper explores how to orchestrate long-running, fault-tolerant agent workflows with built-in governance, observability, retries, and human approvals. See how Agentspan compares to LangGraph, CrewAI, and AutoGen for real-world enterprise AI systems. If you’re building AI workflows that need reliability, scale, and control, this guide shows the architecture patterns that make production-grade agents possible.
A single season of a Netflix show can generate over 2,000 hours of raw footage. That’s 216 million frames.
When a film editor needs to find the exact moment where a specific character says a specific line in a specific location, they’re facing one of the hardest search problems in all of software engineering. And the solution has surprisingly little to do with building a better AI model. The real challenge, it turns out, is plumbing.
Netflix editorial teams used to lose days searching for specific moments buried in raw production footage. For example, a director might need every shot of a character in a particular setting. A marketing team might want the five most visually striking action sequences across an entire franchise. Finding these moments meant hours of manual scrubbing through thousands of hours of material. Creative momentum would stall in situations like this.
The team that solved this problem built something that looks simple from the outside, just a search bar. But underneath it sits a three-layer pipeline that orchestrates an ensemble of AI models, fuses their outputs across a shared timeline, and serves hybrid text-and-vector queries at sub-second latency.
When those multiple AI models run over the same footage, the baseline of 216 million frames explodes into billions of multi-layered data points. Storing, aligning, and intersecting that volume while maintaining sub-second query performance goes well beyond what any traditional database can handle alone.
In this article, we will understand how Netflix built this system and the challenges it faced.
Disclaimer: This post is based on publicly shared details from the Netflix Engineering Team. Please comment if you notice any inaccuracies.
Why Multiple Models
Why would Netflix run multiple AI models over the same footage instead of relying on one powerful model that does everything?
This is because specialized models consistently outperform generalists at their particular task. A model trained specifically for face recognition will identify characters more accurately than a general-purpose vision model. A model tuned for scene classification will map environments more precisely. A dialogue transcription model will capture speech more reliably.
Therefore, Netflix runs an ensemble of specialists. For example, one model recognizes characters. Another classifies scenes and environments. A third transcribes dialogue. A fourth detects objects. Each model is excellent at its job, but each one also produces a fundamentally different kind of output.
For reference, a character recognition model might output a text label like “Joey.” In contrast, a scene classification model produces a 512-dimensional vector embedding, which is basically a list of numbers that represents the mathematical “meaning” of a scene in a way that machines can compare. On the other hand, a dialogue model outputs timestamped transcript text. These are entirely different data types, and they require different search strategies to query.
See the diagram below:
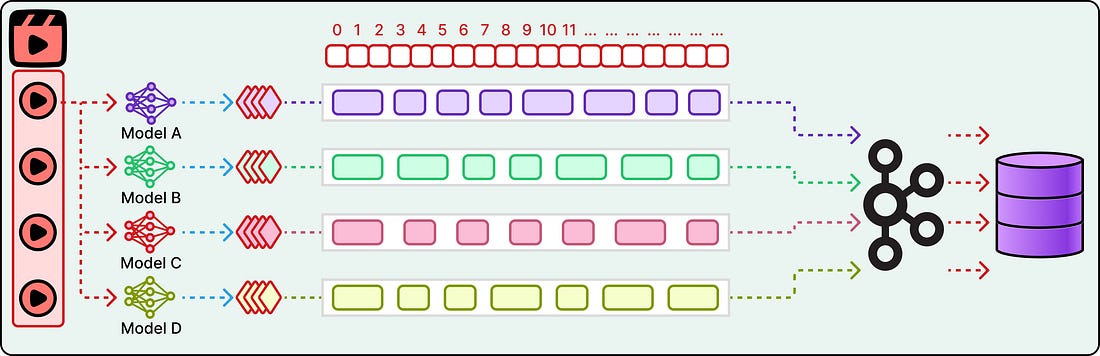 |
The format problem is only half the challenge. Each model also slices the video into different, overlapping time intervals. The character model might detect “Joey” from seconds 2 through 8. The scene model might detect “kitchen” from seconds 4 through 9. There is no shared timeline across models. The intervals overlap, but they don’t align.
So, if we think about it, the engineering team had to solve one core challenge.
How do you take all these different outputs, produced at different time resolutions, in different formats, and merge them into one searchable index?
Netflix is also exploring a fundamentally different approach to this problem through a single unified foundation model called MediaFM that handles audio, video, and text together. Whether the future favors specialized ensembles or unified generalists remains an open question in multimodal AI. But for now, the production system relies on a three-stage pipeline that treats each concern separately.
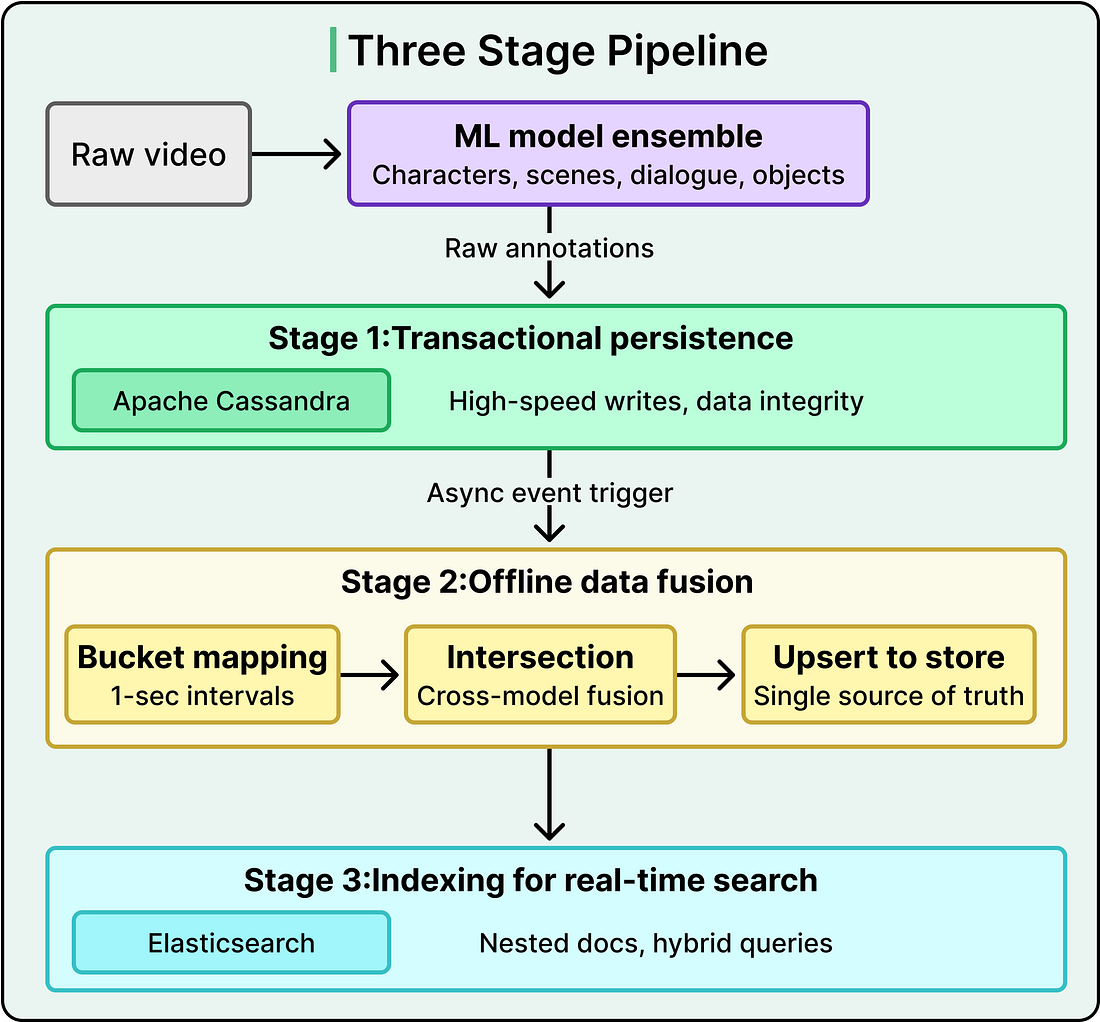
The Three-Stage Pipeline
The transition from raw model output to searchable intelligence follows a decoupled, three-stage process.
Each stage handles one concern and one concern only. This separation is the architectural backbone of the entire system, and it exists because coupling any two stages would create bottlenecks at Netflix’s scale.
 |