|
ScyllaDB Founders Share What Real-Time AI Requires from the Database (Sponsored)
AI is pushing databases to their limits; learn what it takes to stay ahead
 |
AI workloads are exposing the limits of what most databases were designed to handle. Databases will need to process petabytes of data, millions of writes per second, and data types like vectors – all while delivering consistent sub-millisecond P99 latency.
Join ScyllaDB co-founders Dor Laor (CEO) and Avi Kivity (CTO) to explore what real-time AI workloads actually require, and what it takes to stay ahead.
You will learn:
How AI workloads are shifting in real-world applications
The specific pressures these new patterns place on databases
What architectural features help teams meet AI’s demands
In early 2023, the Databricks rate limiter ran on a simple architecture. An Envoy ingress gateway made calls to a Ratelimit Service, which in turn queried a single Redis instance. The setup handled the traffic it was designed for, and the per-second nature of rate limiting meant the counts could stay transient without any durability guarantee.
Then, the real-time model serving was launched. A single customer could now generate orders of magnitude more traffic than the service was built for, and three specific cracks appeared.
Tail latency climbed sharply under load, worsened by two network hops and a P99 of 10 to 20 milliseconds between services in one cloud provider.
Adding machines and bolting on caches stopped helping past a certain point.
The single Redis instance also represented a single point of failure that the team could no longer tolerate.
The team redesigned the service, and the rebuild merits attention because the most interesting part is what they chose to give up.
Strict accuracy is expensive at scale, and Databricks traded it for a faster critical path, a horizontally scalable counter, and a rate limiter that answers as if the decision has already been made by the time the client checks.
In this article, we look at how Databricks implemented rate limiting at scale, how they shrank the critical path, and the accuracy tradeoff that shrinking usually requires.
Disclaimer: This post is based on publicly shared details from the Databricks Engineering Team. Please comment if you notice any inaccuracies.
A Counting Problem
Strip away the framing, and rate limiting reduces to a counting problem. Each request arrives, the system locates the right counter, compares it against a threshold, and either allows or rejects the request. The design question is where that counter is stored and how quickly it works.
In the old Databricks architecture, the counter was stored in Redis. See the diagram below:
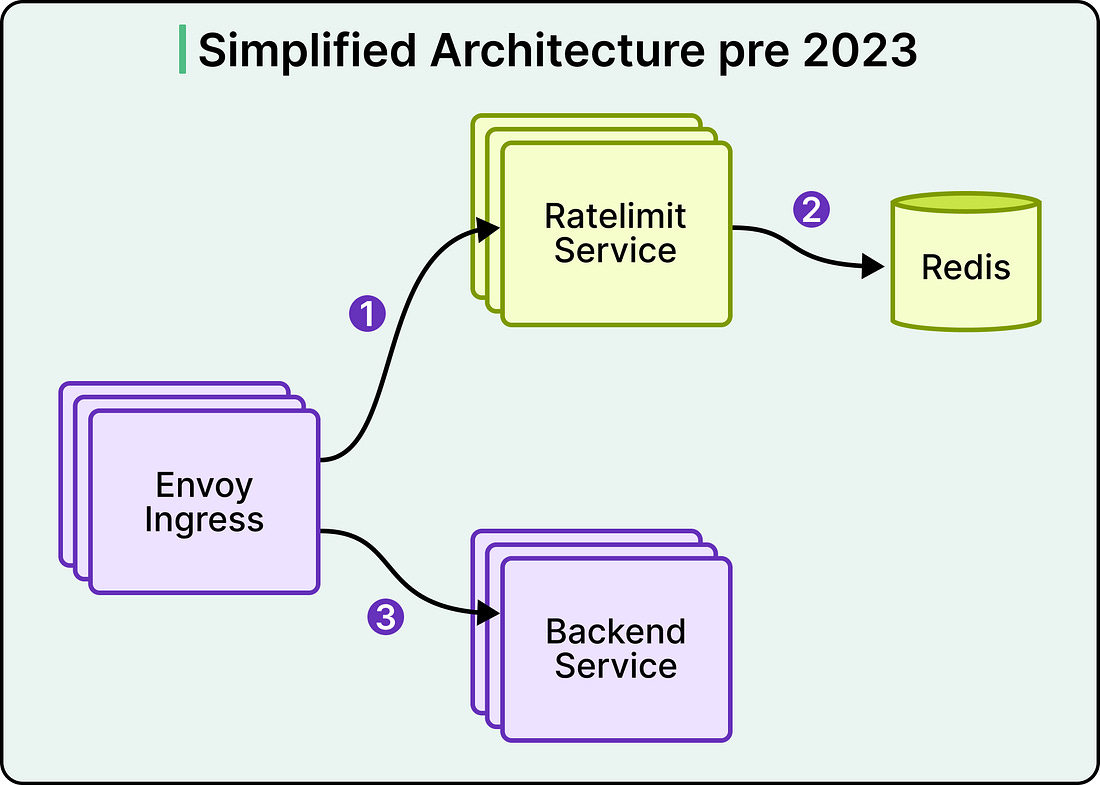 |
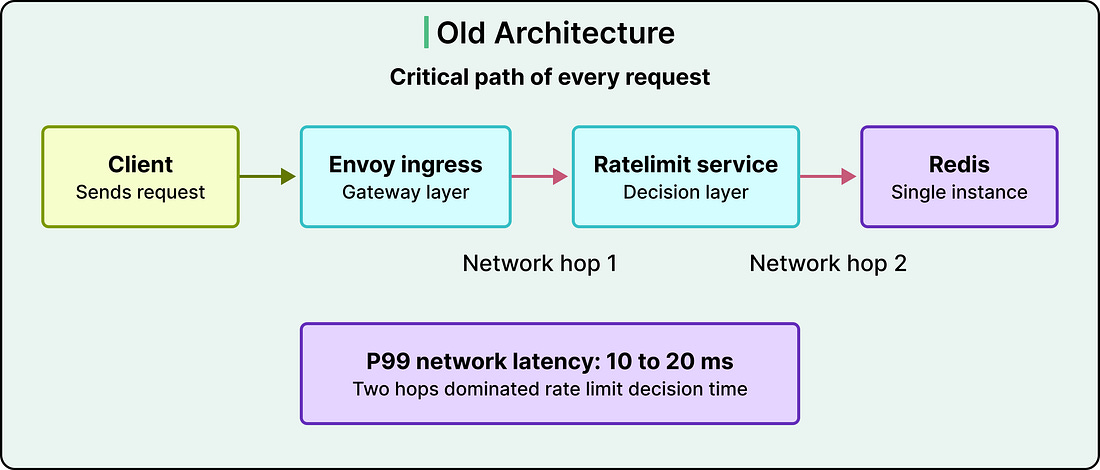
A request flowed through Envoy, hit the Ratelimit Service, and triggered a call to Redis. That meant two network hops on the critical path of every request. In a cloud provider where P99 network latency sat between 10 and 20 milliseconds, those hops dominated the rate limit decision time. A check that should have cost microseconds was costing tens of milliseconds.
See the diagram below:
 |
The team had already tried to work around this. Envoy can be configured with consistent hashing so that requests with the same key land on the same Ratelimit Service instance, which lets that instance keep a local count. The approach helped, but it hit three walls.
Non-Envoy services could not participate in the scheme, which fragmented the rate limit view.
When the service cluster scaled up or restarted, the hash assignments churned, which forced regular syncs back to Redis.
Lastly, consistent hashing can be prone to hotspotting, where one very popular key saturates a single machine while its neighbours sit idle. The only way to push through those hotspots was to over-provision the entire cluster.
This is where scaling stops being additive. Adding machines stopped moving the latency numbers, and adding more caching introduced more inconsistency. The architecture itself was the ceiling, and the team had to change it.