|
Harness engineering for agentic code review (Sponsored)
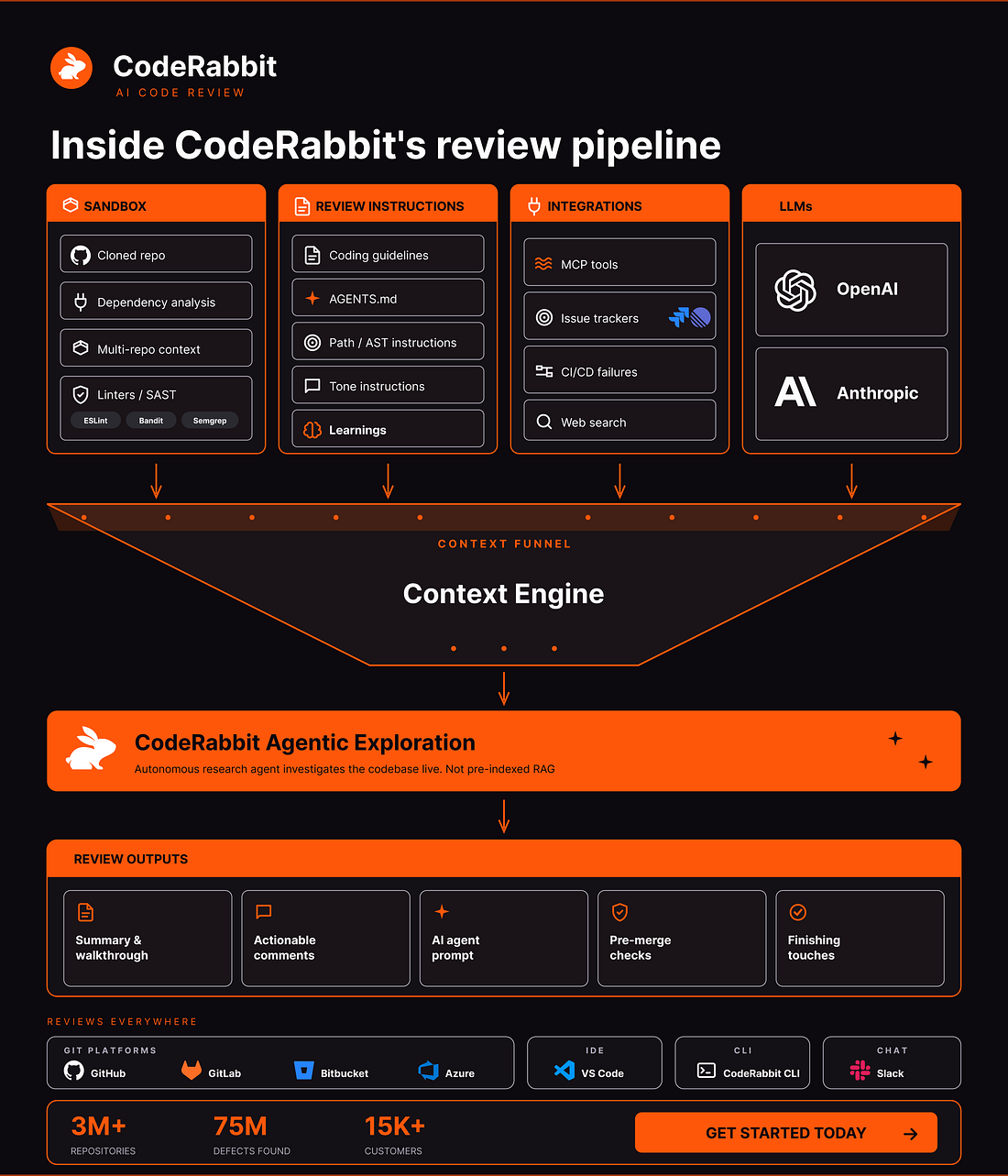 |
Underneath every review sits a purpose-built, independent context engine. It’s the layer that decides what the agent actually sees before a single token of generation happens.
Purpose-built because code review demands a different context than chat or autocomplete: placing the relevant context fragments assembled for each review.
The engine assembles inputs across four planes:
Sandbox. Cloned repo, dependency analysis, multi-repo context and linters/SAST (ESLint, Semgrep) running on the change.
Review instructions. Your coding guidelines, AGENTS.md, path, and AST-scoped rules, tone, and learnings from past reviews.
Integrations. MCP tools, issue trackers (Jira, Linear), CI/CD failures, and web search.
LLMs. Routing across OpenAI and Anthropic.
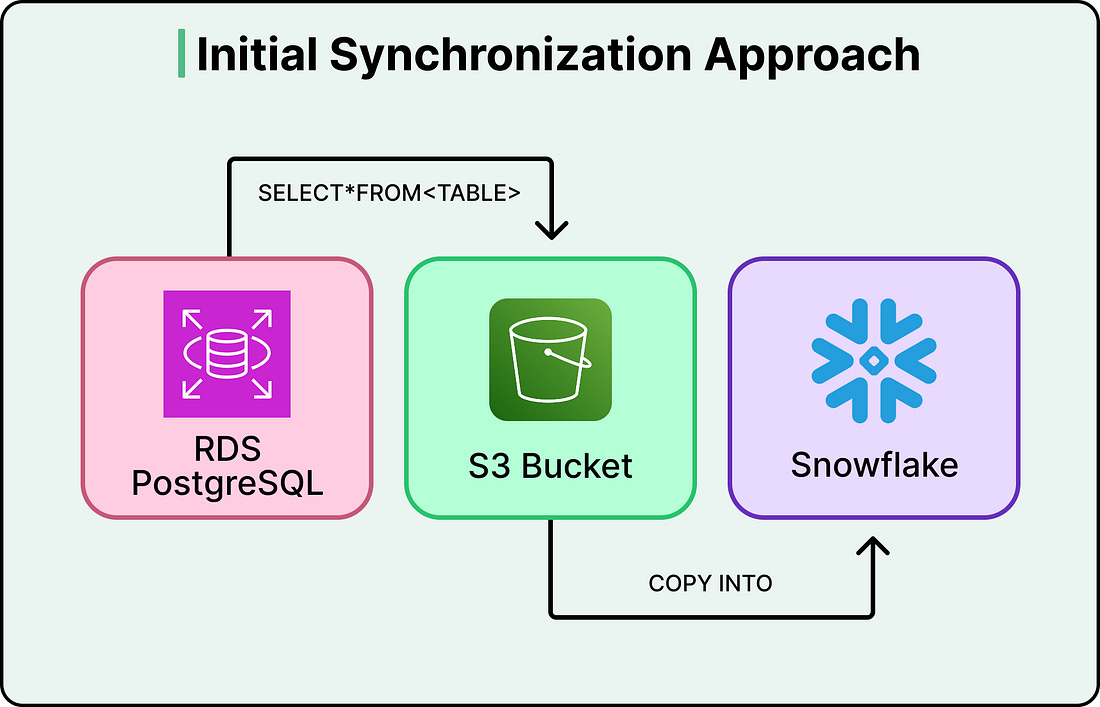
In 2020, Figma’s data synchronization architecture was about five lines of logic. A cron job ran once a day, queried every row from a database table, dumped it into S3, and loaded it into Snowflake.
It was straightforward, easy to reason about, and it worked.
Three years later, that same simplicity was costing Figma millions of dollars a year and leaving their analytics team looking at data that was already days old by the time they could query it.
For reference, Figma is a collaborative design platform where teams create, prototype, and iterate on user interfaces together in real time. If you’ve used a modern app or website, there’s a high chance the screens were designed in Figma or that Figma was part of the workflow.
Since its early days, the product has expanded well beyond its core design tool. FigJam added collaborative whiteboarding in 2021. Dev Mode launched in 2023 to bridge the gap between designers and developers. Figma Make brought AI-powered app prototyping into the mix. The company also localized for the Brazilian, Japanese, Spanish, and Korean markets.
All of that growth meant an explosion in the volume and complexity of data flowing through Figma’s systems every day.
In this article, we will learn what happened as Figma grew and how its engineering team handled the growth in terms of the data pipeline issues.
Disclaimer: This post is based on publicly shared details from the Figma Engineering Team. Please comment if you notice any inaccuracies.
When SELECT * Becomes Your Bottleneck
Figma’s original data pipeline did what’s called a full sync. Every run copied the entire contents of a database table, regardless of how much had actually changed since the last run. If a table had ten million rows and only fifty changed that day, the pipeline still copied all ten million. When tables are small, this is fast and cheap.
To start with, Figma’s production databases were hosted on Amazon RDS PostgreSQL and served live user traffic. Every time someone opens a file, saves a change, or loads a project, those databases handle the request. Running heavy analytical queries on these same databases, things like computing company-wide KPIs or analyzing usage trends across millions of users, would compete with live traffic and slow down the product. So like most companies at this scale, Figma maintains a separate analytics warehouse in Snowflake, a database built specifically for these kinds of large, complex queries. The catch is that data has to get from one to the other. That transfer is the synchronization pipeline.
 |
But Figma’s tables didn’t stay small.
As mentioned, between 2021 and 2025, they launched FigJam, Dev Mode, Figma Make, and expanded localization to serve the Brazilian, Japanese, Spanish, and Korean markets. The user base grew rapidly, and so did the data.
By 2023, daily synchronization tasks were taking around six hours to complete. The largest tables took several days. To make things worse, the pipeline required dedicated database replicas just to handle the export load without affecting production traffic. Those replicas alone cost millions of dollars annually.
Figma evaluated three options to handle this:
They could keep the existing system, but sync delays and replica costs made that untenable.
They could add parallelism to speed up the full copies, but this was a band-aid that wouldn’t scale as tables continued to grow.
Or they could overhaul the pipeline entirely.
They chose the overhaul, committing to incremental synchronization. Instead of copying entire tables every run, they’d capture only what changed and apply those changes to the destination. The concept is simple, but the execution is not.
Incremental Synchronization
Incremental synchronization flips the model. Rather than asking “what does the whole table look like right now?” it asks “what changed since last time?” Only the inserts, updates, and deletes since the last sync get transferred and applied. For a table with ten million rows where fifty changed, you’re now moving fifty rows instead of ten million.
The mechanism that makes this possible is called Change Data Capture, or CDC. Every database keeps an internal log of every write operation, known as the write-ahead log, for its own crash-recovery purposes. CDC reads that log and converts it into a stream of change events. This does not add overhead to the database, and we are piggybacking on bookkeeping that the database is already doing.
The diagram below shows how CDC works on a high-level: