|
New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)
 |
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
In 2021, the Instacart search team faced a problem they could trace to their users’ typing habits. One group of shoppers searched for items like “pesto pasta sauce 8oz” and expected the exact product to appear. Another group searched for things like “healthy foods” and expected the system to understand what they meant. These are genuinely different problems. The first asks for precise keyword matching. The second asks the system to grasp intent from vague language.
Solving both required two different retrieval systems running in parallel. One handled keyword search. The other handled semantic search, where meaning rather than exact words drives the result. The setup worked, and for a while it worked well. But maintaining two systems in sync, blending their results into a single ranked list, and keeping both fast enough for millions of daily queries became a tax that grew heavier each quarter.
In this article, we will learn how Instacart’s search infrastructure evolved over the years and the challenges its engineering team faced.
Disclaimer: This post is based on publicly shared details from the Instacart Engineering Team. Please comment if you notice any inaccuracies.
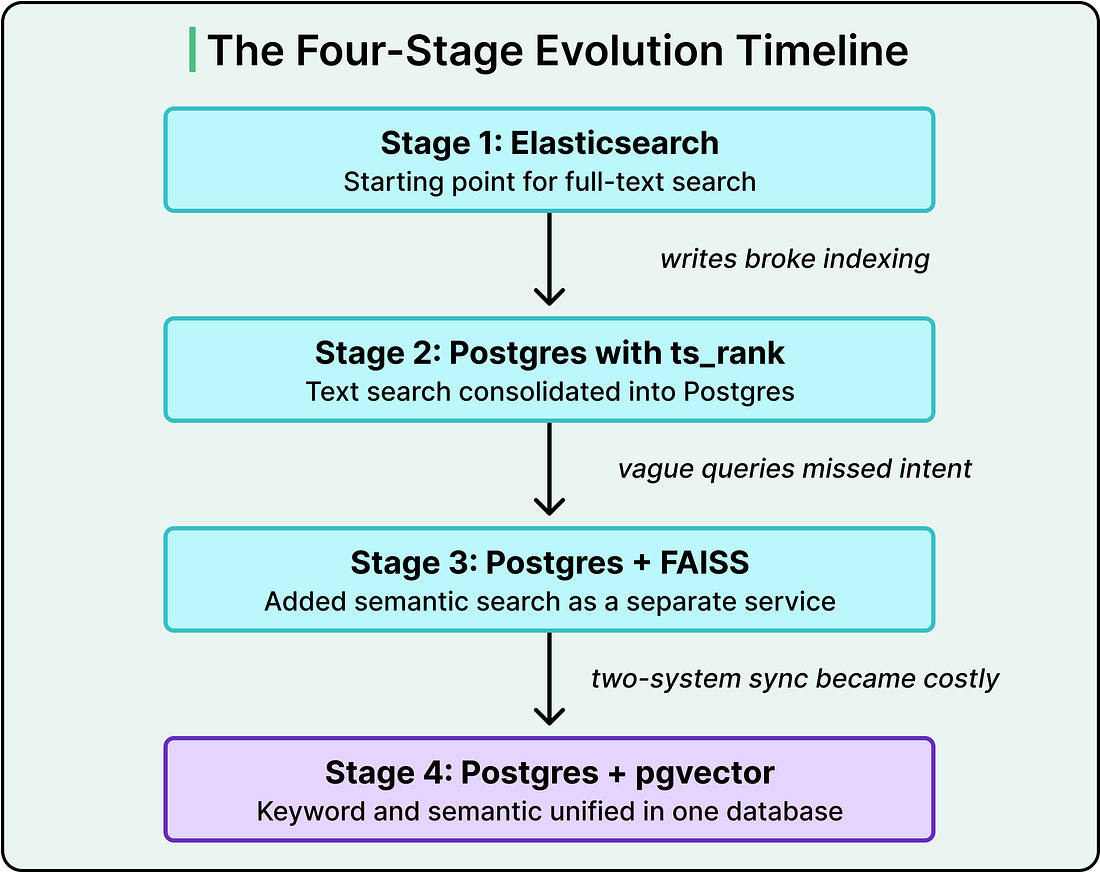 |
The Shape of Search at Instacart
Before looking at the technical choices, it helps to understand the workload Instacart’s search has to serve. A catalog with billions of items stretches across thousands of retailers. The system handles millions of search requests every day, with query volume swinging widely from hour to hour.
What makes their problem genuinely unusual is the write side. Grocery items are fast-moving goods. Prices shift multiple times a day. Inventory availability changes as shelves empty and restock. Discounts come and go. As a result, the search database receives billions of writes per day. Those writes include catalog changes, pricing updates, availability data, ancillary tables for ranking and display, personalization signals, and replacement product data.
This combination is crucial. In most search problems, you index once, maybe refresh occasionally, and queries run against a mostly stable dataset. Instacart’s situation inverts this. Their data changes constantly, and every change has to show up in search results within seconds.
Two terms that we should know are precision and recall. Precision is the percentage of retrieved results that are actually relevant. Recall is the percentage of all relevant documents that the system manages to retrieve. A system with high precision returns mostly good results. A system with high recall catches most of the good results that exist. Tuning these tradeoffs is the core game of search, and the architecture determines how much control you have over each.
Agentic Fine-Tuning and Inference with Pioneer (Sponsored)
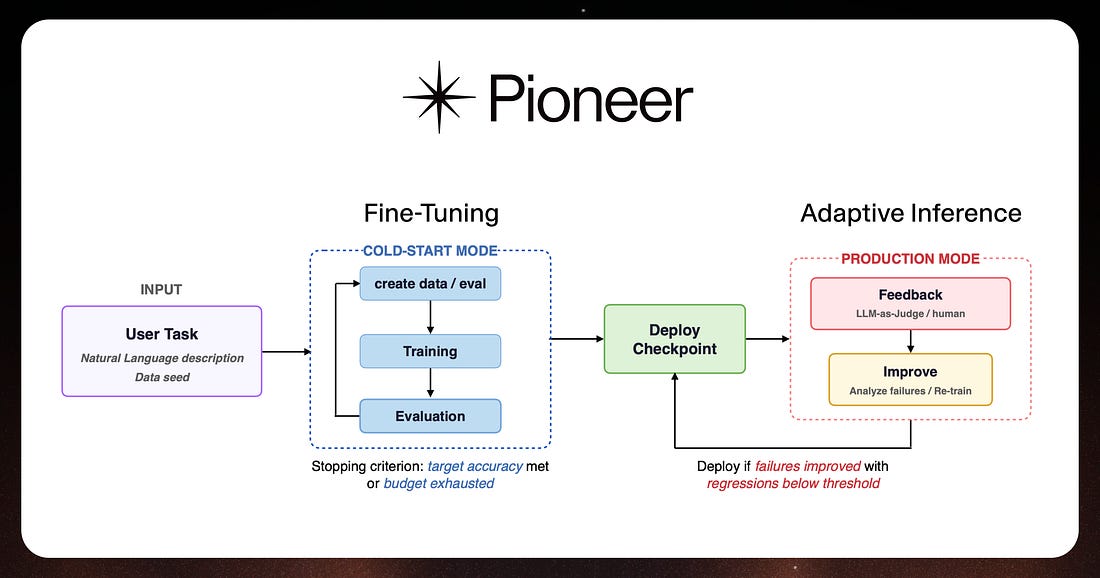 |
Fine-tuning open-source models manually is a slow, tedious task.
Pioneer is a fine-tuning agent that automates the entire process, allowing users to generate synthetic training data, perform LoRA and full fine-tuning runs, run custom evals, and deploy models to production through a chat interface or API. Once deployed, Pioneer autonomously diagnoses failures and retrains on live data in a continuous loop called adaptive inference.
Fastino Labs recently released a technical report evaluating Pioneer’s adaptive inference across eight benchmarks, achieving improvements of up to +83.8 percentage points over base models, with each run completing in 8-12 hours at $12–55.