|
AI inference: 24,240 TPS vs 1,863 TPS H100 (Sponsored)
 |
Most teams optimize models. Few optimize inference. We benchmarked NVIDIA RTX PRO 6000 Blackwell on Akamai Cloud against H100 using real LLM workloads.
At 100 concurrent requests, Blackwell reached 24,240 tokens/sec per server, compared to 1,863 TPS on H100. That’s up to 1.63× higher throughput, with additional gains from FP4 precision.
The difference comes down to architecture. These GPUs run on a globally distributed platform built for real-time, latency-sensitive inference, not centralized batch jobs.
If you're building agentic systems or high-concurrency AI apps, infrastructure choices matter as much as model selection. See the full setup, methodology, and results. View benchmark results
In 2024, Wise’s deployment system automatically blocked hundreds of releases that would have caused production incidents.
There was no human intervention, but the system routed just 5% of traffic to the new version, watched technical and business metrics for 30 minutes, and rolled back when it detected anomalies. Three years earlier, Wise was deploying with a simpler in-house tool that treated each release as a basic transaction, where the process was essentially to push the code and hope for the best.
This leap was made possible by some interesting engineering decisions that we will learn about in this article.
For reference, Wise moves about £36 billion across borders every quarter, with 65% of transfers arriving instantly. One might assume that kind of reliability requires a tightly controlled, top-down engineering organization. However, the opposite is true.
Wise has 850+ engineers organized into autonomous squads, each empowered to make their own technical decisions. The reason this works, and the reason it would collapse without a very specific set of infrastructure investments, is the real engineering story behind Wise.
Behind the product that 15.6 million active customers interact with, there are over 1000 microservices, 700+ Java repositories, 40 web applications, and native iOS and Android apps with hundreds of modules each. What holds all of this together is an internal platform, a set of shared tools, frameworks, and automated systems that make the right engineering choice the easy one.
 |
Disclaimer: This post is based on publicly shared details from the Wise Engineering Team. Please comment if you notice any inaccuracies.
Standardizing the Starting Point
When a system has 1000+ services owned by dozens of independent teams, the most dangerous form of complexity is inconsistency. If every team wires up security, database connections, Kafka consumers, and logging differently, you end up with 1000 slightly different systems that are all hard to debug, upgrade, and secure.
Wise’s answer to this is a microservice chassis framework, an opinionated, pre-configured foundation that every new backend service can start from. The chassis handles security, observability, database communication, Kafka integration, and more, all with recommended defaults so that teams can focus on business logic rather than plumbing.
What makes Wise’s approach distinct is that the chassis is shipped as a versioned artifact rather than a template you fork and modify.
The difference matters. With a template, the service diverges from the standard the moment you create it. With an artifact dependency, updates to the chassis flow downstream when teams bump the version. Security patches, observability improvements, and new defaults reach services through a regular dependency upgrade rather than a manual migration.
This approach also extends to the build pipeline.
Wise built a collection of in-house Gradle plugins, including one that standardizes GitHub Actions workflows. When Wise decided to roll out SLSA (a framework for protecting software supply-chain integrity) across the organization, it became a plugin version update across 700+ Java repositories rather than 700 individual pull requests.
On top of this, a language-agnostic automation service can make complex changes across the codebase at scale and create pull requests for the owning team to review. Dependency upgrades for Java services are now fully automated through this system.
The same standardization mindset shows up on the frontend.
Wise’s web applications are built on CRAB, a Wise-specific abstraction on top of Next.js, split across 40 distinct apps that handle specific product functions. Visual regression testing is handled by Storybook paired with Chromatic, which captures snapshots of React components after each change and highlights visual differences to catch UI bugs before they reach customers.
Shipping Code Safely
Standardizing how services are built is only half the problem. The other half is standardizing how they reach production.
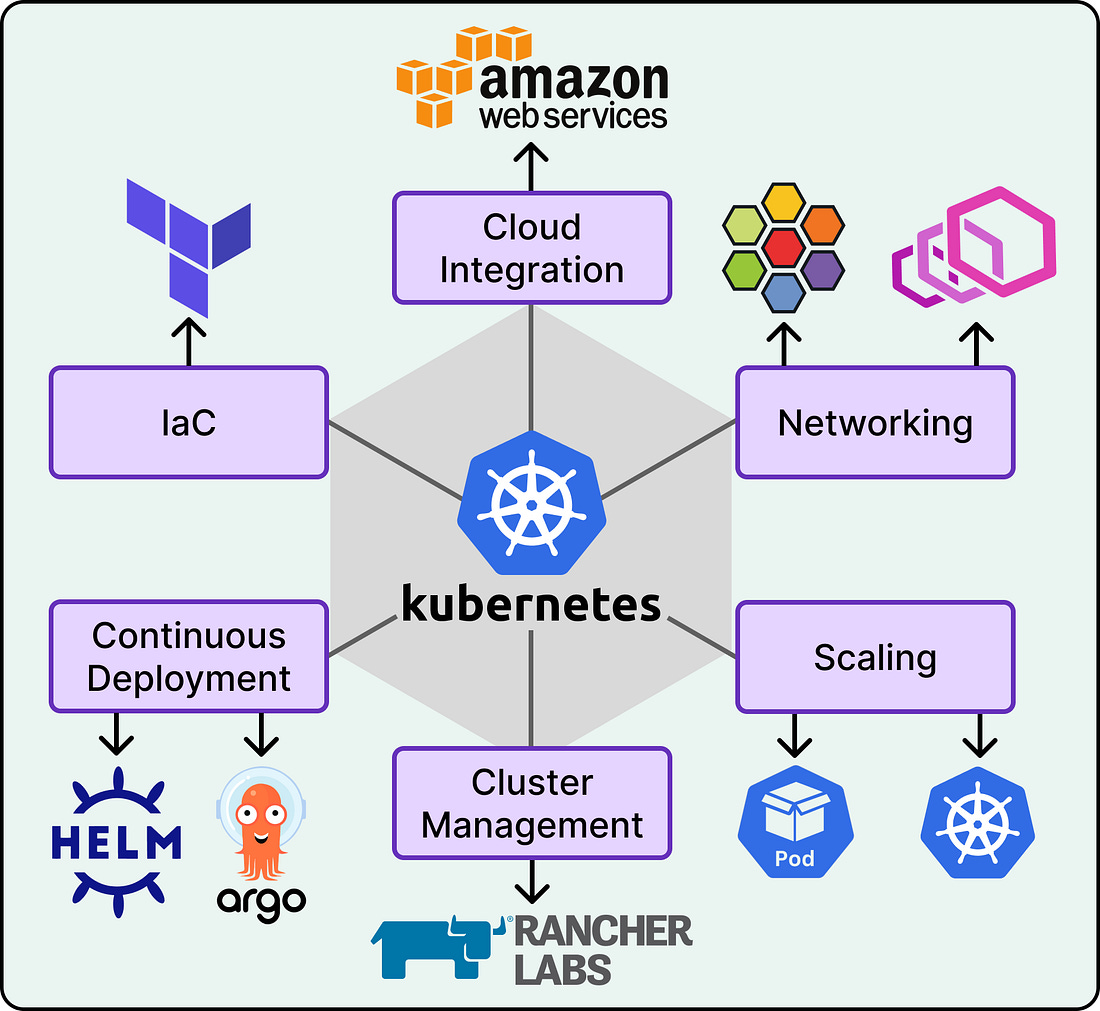
Since 2018, Wise has relied on Kubernetes to host its services, originally built with Terraform, JSONNET, and ConcourseCI. That setup supported service-mesh controls through Envoy, PCI-DSS compliance, and frictionless deployments for several years.
But as Wise grew, the original approach could not scale further without becoming a maintenance burden. This led to the Compute Runtime Platform (CRP), a ground-up rebuild of Wise’s Kubernetes infrastructure. Terraform still provisions infrastructure, but the codebase was rewritten from scratch for flexibility. RKE2 now handles cluster bootstrapping, with Rancher managing overall cluster state. Helm replaced JSONNET for better maintainability and upstream compatibility. ArgoCD with custom plugins ensures fully automated provisioning and consistency across environments. The result is that Wise grew from 6 Kubernetes clusters to more than 20 while keeping maintenance manageable.