|
Model Manipulation: The New Acquisition Channel No One Expected
Or maybe less from the flock thought about
The AI notepad for people in back-to-back meetings (Sponsor)
 |
Most AI note-takers just transcribe what was said and send you a summary after the call.
Granola is an AI notepad. And that difference matters.
You start with a clean, simple notepad. You jot down what matters to you and, in the background, Granola transcribes the meeting.
When the meeting ends, Granola uses your notes to generate clearer summaries, action items, and next steps, all from your point of view.
Then comes the powerful part: you can chat with your notes. Use Recipes (pre-made prompts) to write follow-up emails, pull out decisions, prep for your next meeting, or turn conversations into real work in seconds.
Think of it as a super-smart notes app that actually understands your meetings.
Free 1 month with the code SCOOP
Over the past decade, the internet’s dominant growth funnel has been built around search engines. Users would search for information, click through links, and eventually convert into customers. This model, deeply rooted in the principles of search engine optimization (SEO), has created an entire industry.
However, the landscape is shifting. Large language models (LLMs) such as ChatGPT, Claude, Gemini, and Grok are quickly becoming the go-to source of information, surpassing traditional search engines in many use cases. Instead of presenting users with a list of links, LLMs provide a synthesized answer in real-time. This evolution is fundamentally altering how products and services get discovered.
The new challenge is no longer about ranking highly in search results. It’s about ensuring that your product is the one selected in a language model’s generated answer. As LLMs grow in usage, the ability to manipulate these models’ responses has become a critical issue, leading to what is now being called model manipulation.
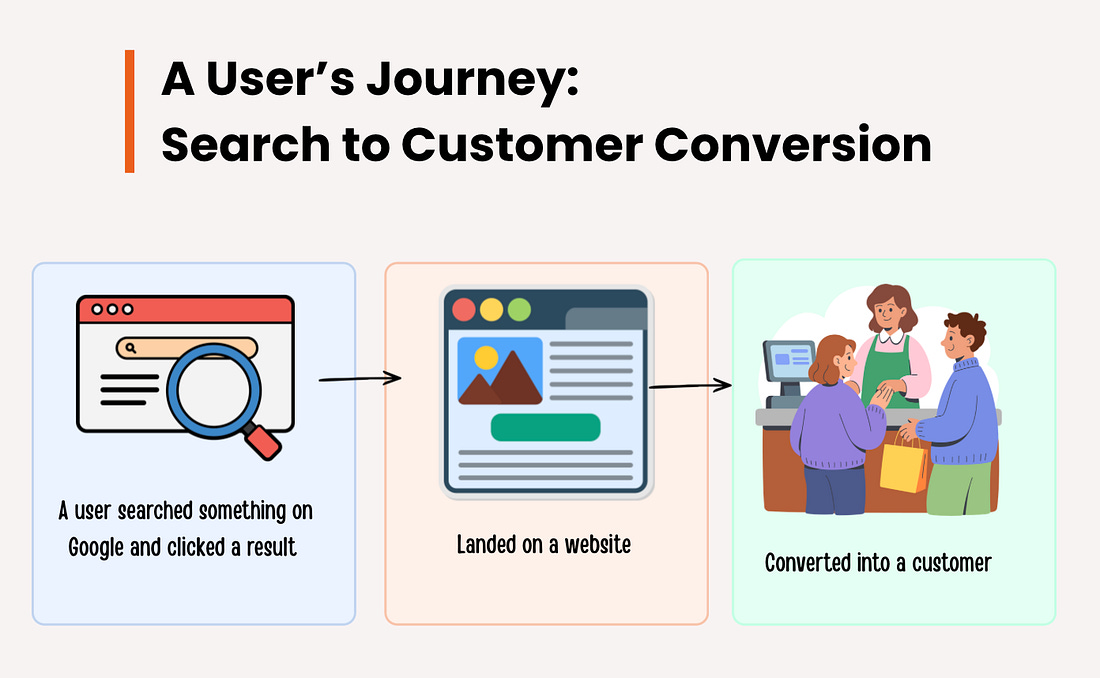 |
The Old vs New Internet Discovery Model
Traditional Search Funnel
User Question
↓
Search on Google
↓
10 Search Results
↓
User clicks a link
↓
Website visit
↓
Conversion
LLM Discovery Funnel
User Question
↓
Ask AI (ChatGPT / Claude / Gemini)
↓
Single synthesized answer
↓
Product recommendation
↓
User action
The Engineering Problem of Model Manipulation
At its core, model manipulation is the process of influencing how language models generate responses to user queries by strategically injecting biased or manipulated content into the training data. This manipulation is subtle but powerful, as LLMs are trained to recognize and prioritize patterns in language.
Given the sheer scale of data LLMs are trained on—often spanning billions of documents—the manipulation doesn’t require large-scale changes. Even small modifications to the training corpus can significantly alter the behavior of a model.
For instance, companies may flood the internet with content that promotes their product, such as sponsored reviews, listicles, and forum posts, that influence how LLMs rank certain products or services. The problem becomes exacerbated by the fact that LLMs rely on the statistical frequency of terms rather than the factual accuracy of the data.
This introduces a serious security risk. The manipulative injection of biased content, often called data poisoning, can systematically shape a model’s outputs, making it difficult to discern between authentic and manipulated information.
Understanding How LLMs Are Vulnerable
LLMs, unlike traditional search engines, don’t just retrieve and display ranked links. They generate new text based on the patterns they’ve learned during training. This means they are fundamentally different from search engines like Google, which rank documents based on explicit metrics such as backlinks and engagement.
In a language model, training is driven by statistical analysis. When a model sees a frequent pattern, it “learns” that this pattern is likely to be correct. This makes LLMs highly susceptible to pattern manipulation. A coordinated effort to repeatedly insert certain keywords, phrases, or concepts into the training data can cause the model to prioritize those elements in its answers.
This is what we call data poisoning. Instead of manipulating the model directly, adversaries can manipulate the data it is trained on, influencing its behavior when making future predictions. Since LLMs don’t have an inherent mechanism for validating the truth of the data, they are prone to learning false or biased patterns.