|
New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)
 |
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Nextdoor operates as a hyper-local social networking service that connects neighbors based on their geographic location.
The platform allows people to share local news, recommend local businesses, and organize neighborhood events. Since the platform relies on high-trust interactions within specific communities, the data must be both highly available and extremely accurate.
However, as the service scaled to millions of users across thousands of global neighborhoods, the underlying database architecture had to evolve from a simple setup into a sophisticated distributed system.
This engineering journey at Nextdoor highlights a fundamental rule of system design.
Every performance gain introduces a new requirement for data integrity. The team followed a predictable progression, moving from a single database instance to a complex hierarchy of connection poolers, read replicas, versioned caches, and background reconcilers. In this article, we will look at how the Nextdoor engineering team handled this evolution and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the Nextdoor Engineering Team. Please comment if you notice any inaccuracies.
The Limits of the “Big Box”
In the early days, Nextdoor relied on a single PostgreSQL instance to handle every post, comment, and neighborhood update.
For many growing platforms, this is the most logical starting point. It is simple to manage, and PostgreSQL provides a robust engine capable of handling significant workloads. However, as more neighbors joined and the volume of simultaneous interactions grew, the team hit a wall that was not related to the total amount of data stored, but more to do with the connection limit.
PostgreSQL uses a process-per-connection model. In other words, every time an application worker wants to talk to the database, the server creates a completely new process to handle that request. If an application has five thousand web workers trying to access the database at the same time, the server must manage five thousand separate processes. Each process consumes a dedicated slice of memory and CPU cycles just to exist.
Managing thousands of processes creates a massive overhead for the operating system. The server eventually spends more time switching between these processes than it does running the actual queries that power the neighborhood feed. This is often the point where vertical scaling, or buying a larger server with more cores, starts to show diminishing returns. The overhead of the “process-per-connection” model remains a bottleneck regardless of how much hardware is thrown at the problem.
To solve this, Nextdoor introduced a layer of middleware called PgBouncer. This is a connection pooler that sits between the application and the database. Instead of every application worker maintaining its own dedicated line to the database, they all talk to PgBouncer.
The Request Phase: A web worker requests a connection from PgBouncer to execute a quick query.
The Assignment Phase: PgBouncer assigns an idle connection from its pre-established pool rather than forcing the database to create a new process.
The Execution Phase: The query runs against the database using that shared connection.
The Release Phase: The worker finishes its task, and the connection returns to the pool immediately for the next worker to use.
This allows thousands of application workers to share a few hundred “warm” database connections. This effectively removed the connection bottleneck and allowed the primary database to focus entirely on data processing.
Dividing the Labor and the “Lag” Problem
Once connection management was stable, the next bottleneck appeared in the form of read traffic.
In a social network like Nextdoor, the ratio of people reading the feed compared to people writing a post is heavily skewed. For every one person who saves a new neighborhood update, hundreds of others might view it. A single database server must handle both the “Writes” and the “Reads” at the same time. This creates resource contention where heavy read queries can slow down the ability of the system to save new data.
The solution was to move to a Primary-Replica architecture. In this setup, one database server is designated as the Primary. It is the only server allowed to modify or change data. Several other servers, known as Read Replicas, maintain copies of the data from the Primary. All the “Read” traffic from the application is routed to these replicas, while only the “Write” traffic goes to the Primary.
See the diagram below:
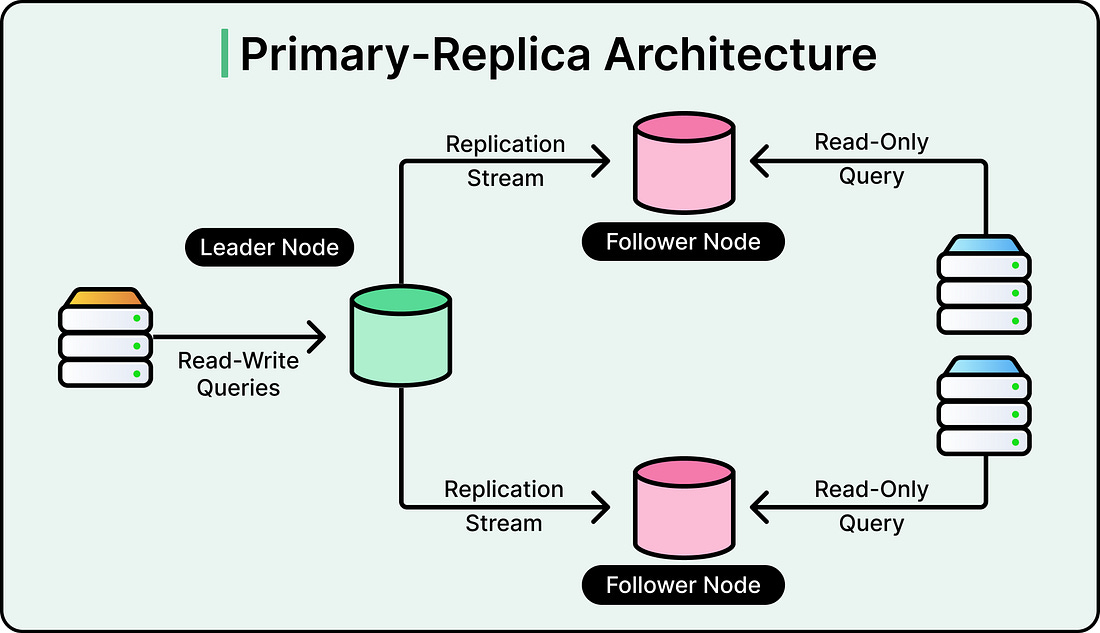 |
This separation of labor allows for massive horizontal scaling of reads. However, this introduces the challenge of Asynchronous Replication. The Primary database sends its changes to the replicas using a stream of logs. It takes time for a new post saved on the Primary to travel across the network and appear on the replicas. This delay is known as replication lag.
See the diagram below that shows the difference between synchronous and asynchronous replication: