|
On-Demand Webinar: Designing for Failure and Speed in Agentic Workflows with FeatureOps (Sponsored)
 |
Join Alex Casalboni (Developer Advocate @ Unleash) for a deep dive on how to design resilient AI workflows to make reversibility a foundational mechanism and release AI-generated code with confidence.
AI writes code in seconds, but reviews take hours. Don’t let this gap slow you down.
Watch our recent webinar to learn how FeatureOps helps you manage risk, contain blast radius, and maintain control over fast-moving agentic workflows.
In this webinar, you’ll learn how to:
Reduce blast radius for AI-generated changes
Separate deployment from exposure at runtime
Build reversibility into agent planning and shipping
Imagine you’re watching a video with AI-generated subtitles. The speaker is mid-sentence, clearly still talking, gesturing, making a point. But the subtitles just vanish, and there are a few seconds of blank screen. Then they reappear as if nothing happened.
This looks like a bug. But it’s a side effect of the AI being too good at translation.
Vimeo’s engineering team ran into this exact problem when they built LLM-powered subtitle translation for their platform. The translations themselves were excellent: fluent, natural, and often indistinguishable from human work. However, the product experience was broken because subtitles kept disappearing mid-playback, and the root cause turned out to be the AI’s own competence.
In this article, we will look at how the Vimeo engineering team overcame this problem and the decisions it made
Disclaimer: This post is based on publicly shared details from the Vimeo Engineering Team. Please comment if you notice any inaccuracies.
Subtitles Are a Timing Grid
A subtitle file is a sequence of timed slots. Each slot has a start time, an end time, and a piece of text. The video player reads these slots and displays text during each window. Outside that window, nothing shows. If a slot is empty, the screen goes blank for that duration.
This means subtitle translation carries an implicit contract that must be followed. If the source language has four lines, the translation also needs to produce exactly four lines. Each translated line maps to the same time slot as the original. Breaking this contract results in empty slots.
LLMs break this contract by default because they’re optimized for fluency. When an LLM encounters messy, but natural human speech (filler words, false starts, repeated phrases), it does what a good translator would do. It cleans things up and merges fragmented thoughts into a single, polished sentence.
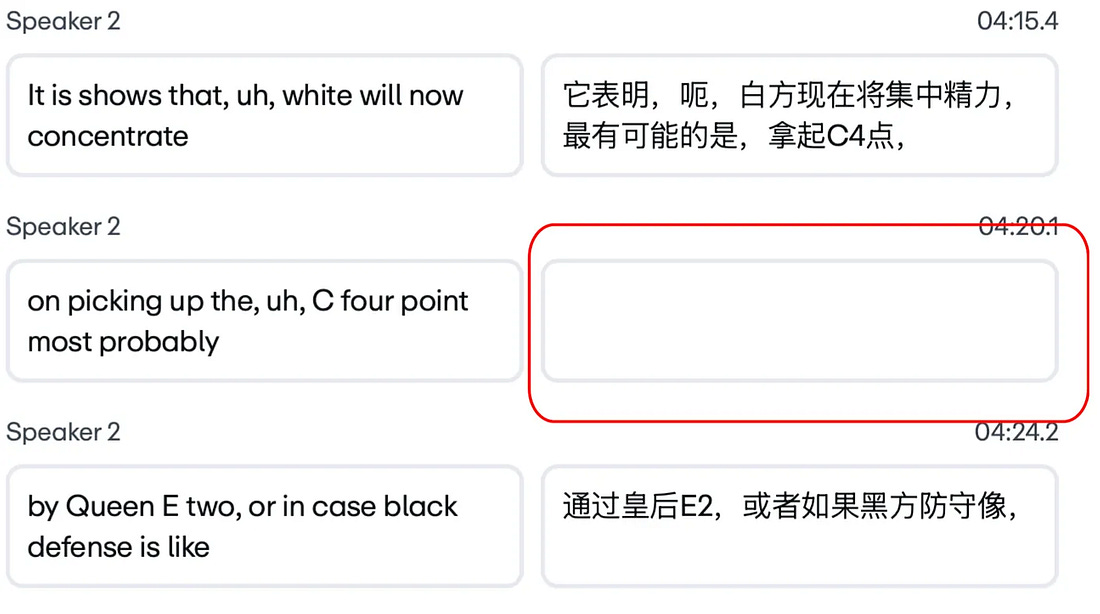
Here’s a concrete example. A speaker in a video says:
“Um, you know, I think that we’re gonna get... we’re gonna remove a lot of barriers.”
That maps to two timed subtitle slots on the video timeline. A traditional translation system handles each line separately, one-to-one. But the LLM recognizes this as a single, fragmented thought and produces one clean Japanese sentence, which is grammatically perfect and semantically accurate. But now the system has two time slots and only one line of text. The second slot goes blank, which means that the subtitles disappear while the speaker keeps talking.
Vimeo calls this the blank screen bug. And it isn’t a rare edge case. It’s the default behavior of any sufficiently capable language model translating messy human speech.
See the picture below:
 |
If you’ve ever built anything that sends LLM output into a system expecting predictable structure (JSON schemas, form fields, database rows), you’ve probably hit a version of this same tension. The model optimizes for quality, and quality doesn’t always respect the structural contract your system depends on.
The Geometry of Language
This problem gets significantly worse when you move beyond European languages.
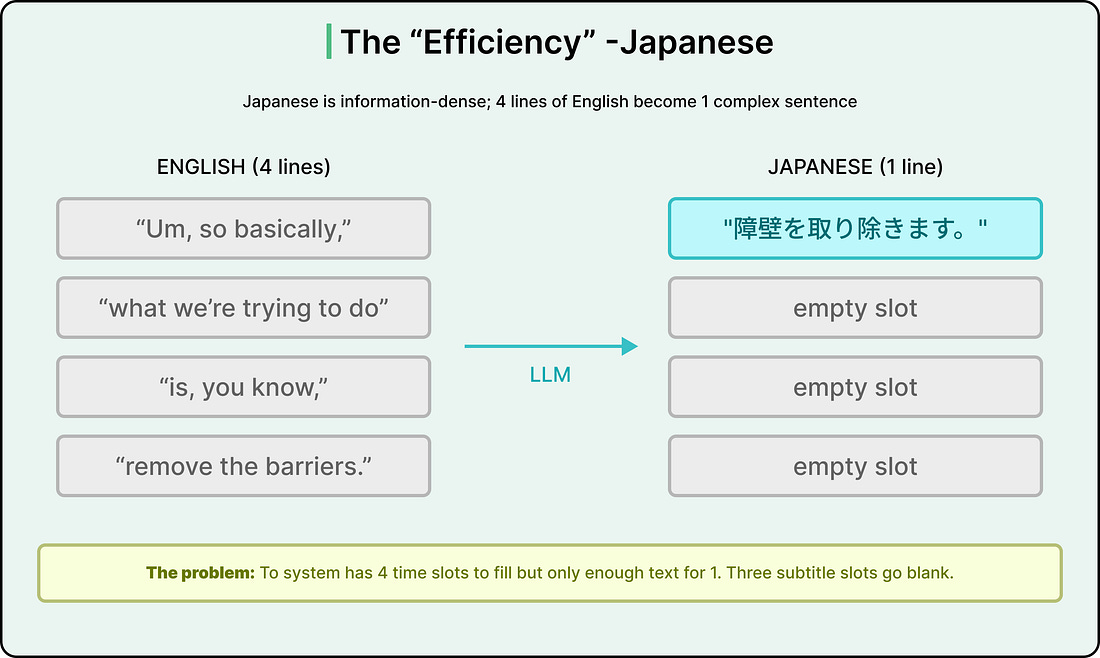
Different languages don’t just use different words. They organize thoughts in fundamentally different orders and densities. Vimeo’s engineering team started calling this “the geometry of language,” and it essentially signifies that the shape of a sentence changes across languages in ways that make one-to-one line mapping structurally impossible in some cases.
For example, Japanese is far more information-dense than English. Where an English speaker might speak four lines of filler (”Um, so basically,” / “what we’re trying to do” / “is, you know,” / “remove the barriers”), a typical Japanese translation consolidates all of that into a single, grammatically tight sentence.
See the example below:
 |