|
Technical Guide: How to Orchestrate Langchain Agents for Production (Sponsored)
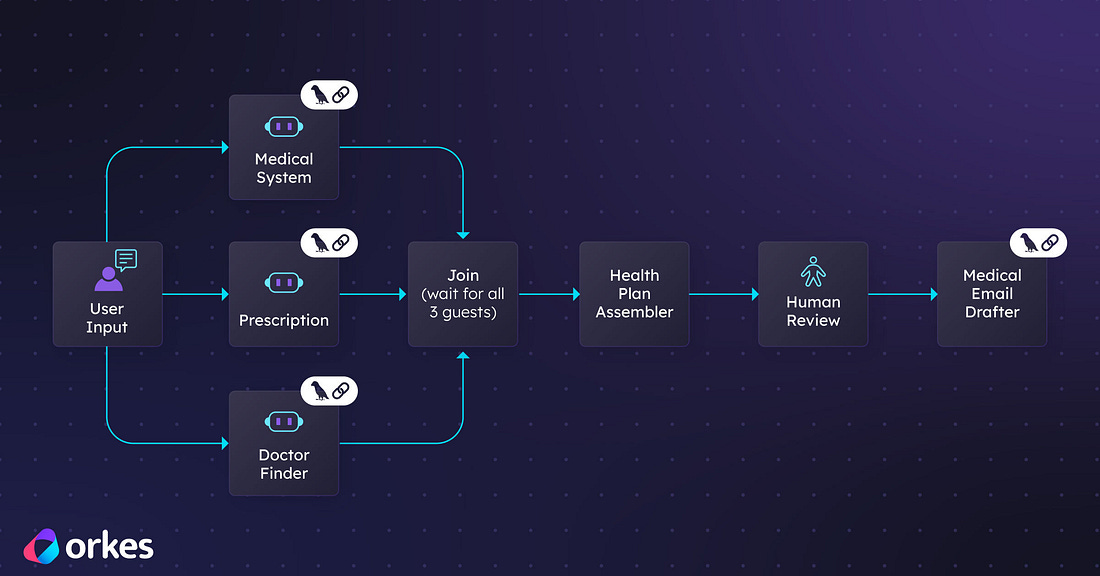 |
Building with LangChain agents is easy. Running them reliably in production is not. As agent workflows grow in complexity, you need visibility, fault tolerance, retries, scalability, and human oversight. Orkes Conductor provides a durable orchestration layer that manages multi agent workflows with state management, error handling, observability, and enterprise grade reliability. Instead of stitching together fragile logic, you can coordinate agents, tools, APIs, and human tasks through a resilient workflow engine built for scale. Learn how to move from experimental agents to production ready systems with structured orchestration.
2026 has already started strong. In January alone, Moonshot AI open-sourced Kimi K2.5, a trillion-parameter model built for multimodal agent workflows. Alibaba shipped Qwen3-Coder-Next, an efficient coding model designed for agentic coding. OpenAI launched a macOS app for its Codex coding assistant. These are recent moves in trends that have been building for months.
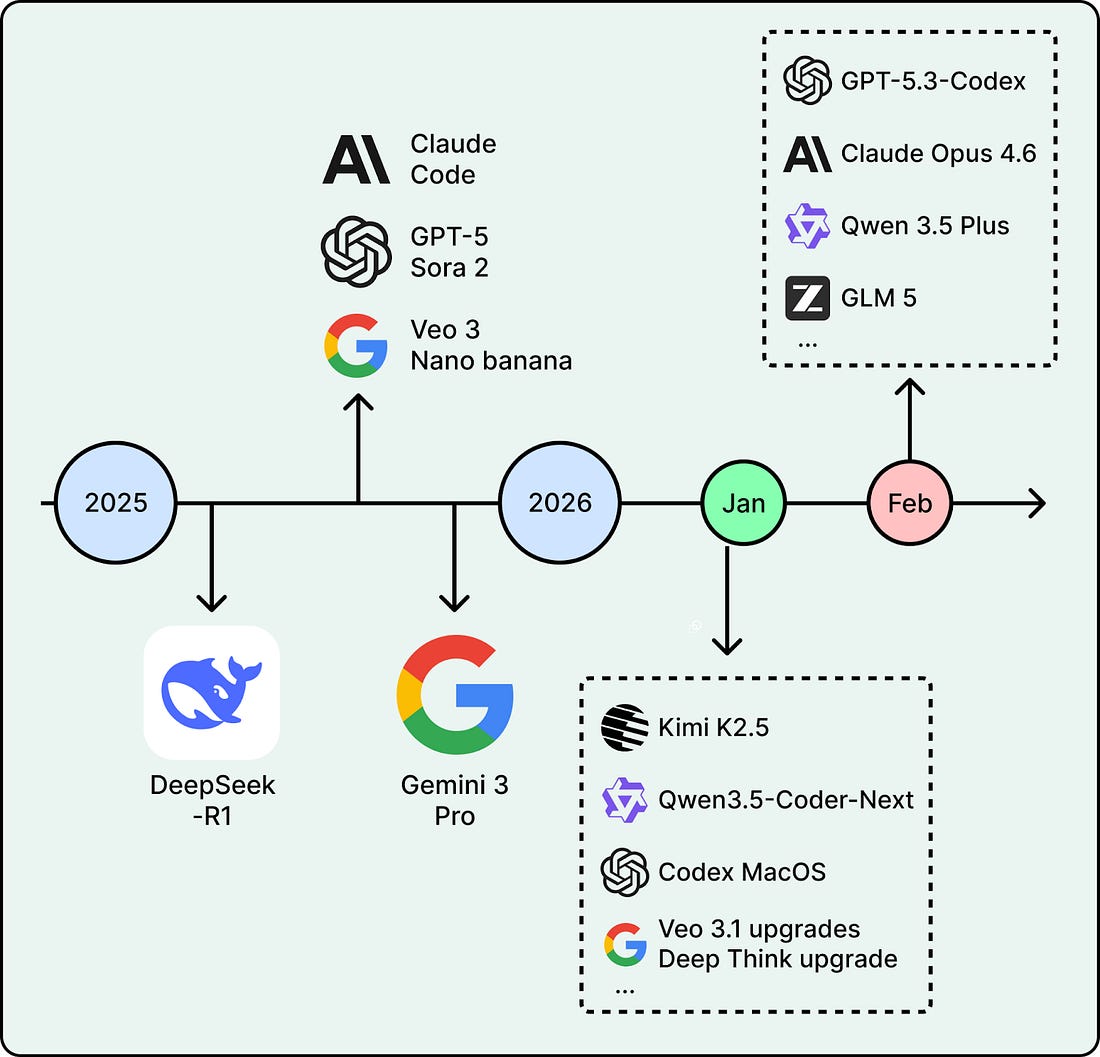 |
This article covers five key trends that will likely shape how teams build with AI this year.
1. Reasoning and RLVR
Early language models like GPT-4 generated answers directly. You asked a question, and the model started producing text token by token. This works for simple tasks, but it often fails on harder problems where the first attempt is wrong, like advanced math or multi-step logic.
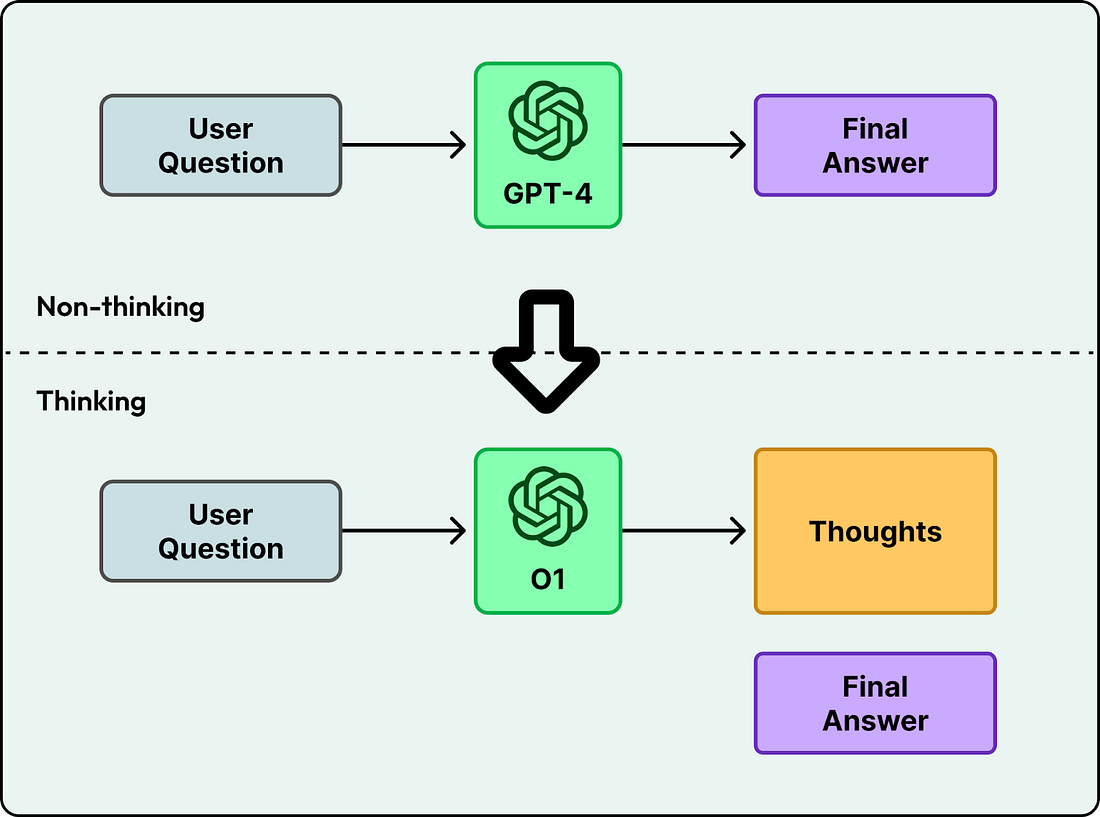 |
Newer models, starting with OpenAI’s o1, changed this by spending time “thinking” before answering. Instead of jumping straight to the final response, they generate intermediate steps and then produce the answer. The model spends more time and computing power, but it can solve much harder problems in logic and multi-step planning.
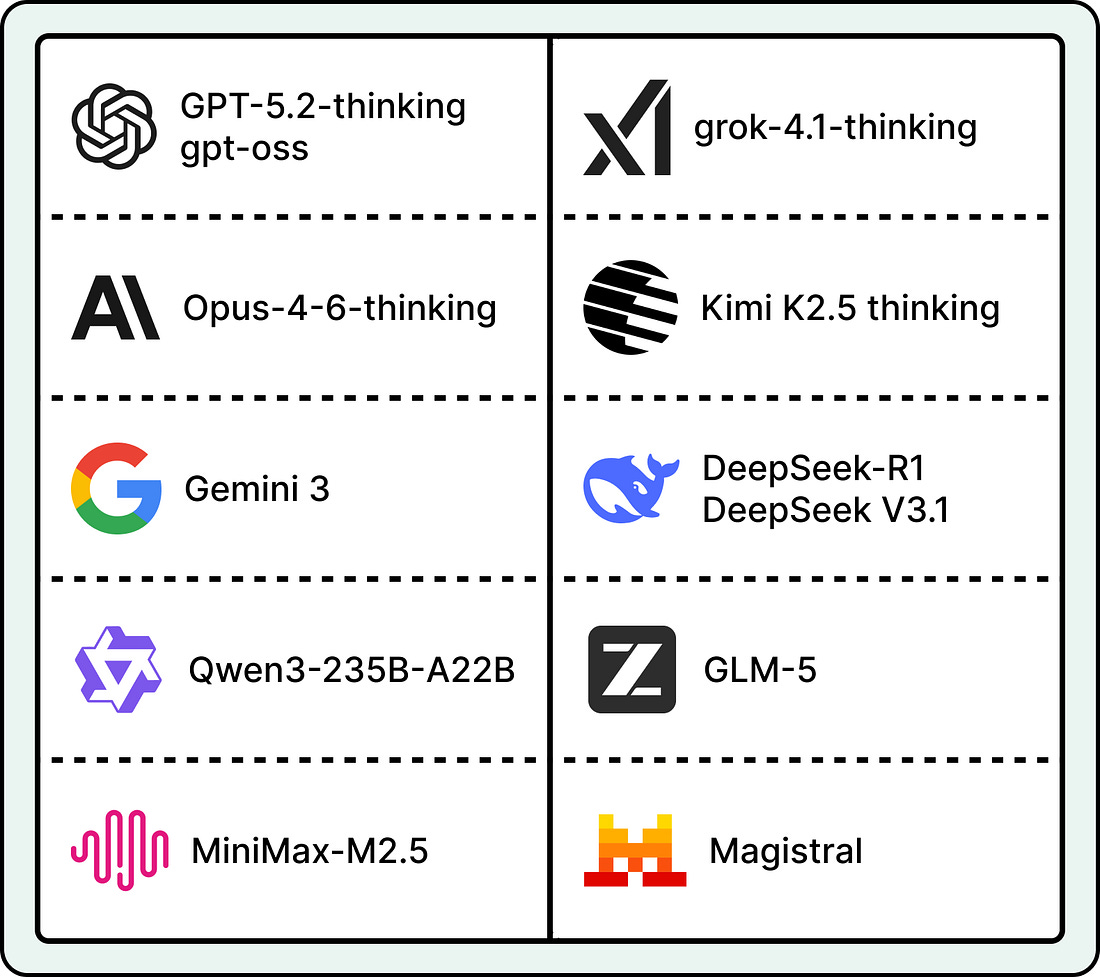
After o1, many teams focused on training reasoning models. By early 2026, most major AI labs had either released a reasoning model or added reasoning to its main product.
 |
What is RLVR
A key method that made model training practical at scale was Reinforcement Learning with Verifiable Rewards (RLVR). Although first introduced by AI2’s Tülu 3, DeepSeek-R1 brought the approach to mainstream attention by applying it at scale. To understand how RLVR improves on previous methods, it helps to look at the standard training pipeline.
LLM training has two main stages: pre-training and post-training. During post-training, a Reinforcement Learning (RL) algorithm lets the model practice. The model generates responses, and the algorithm updates its weights so better responses become more likely over time.
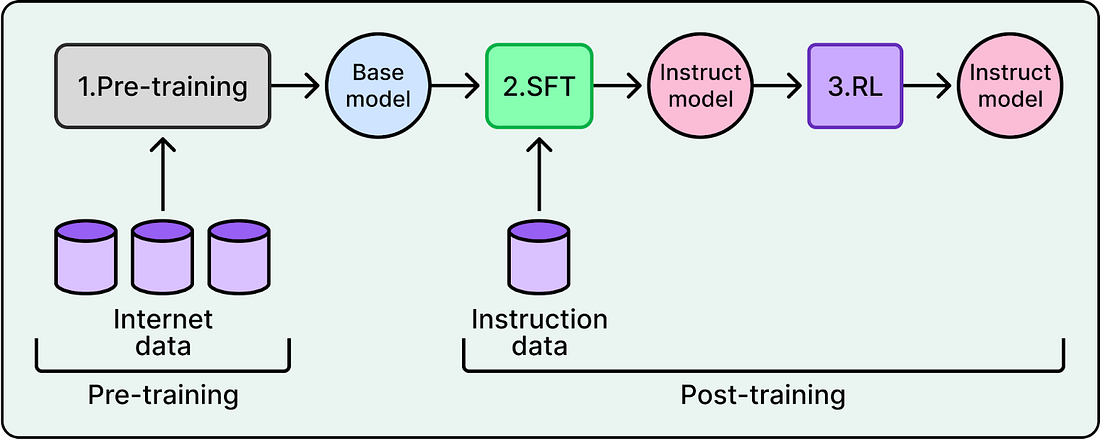 |
To decide which responses are better, AI labs traditionally trained a separate reward model as a proxy for human preferences. This involved collecting preference data from humans, training the reward model on that data, and using it to guide the LLM. This approach is known as Reinforcement Learning from Human Feedback (RLHF).