General Availability
Hi dobry juzer,
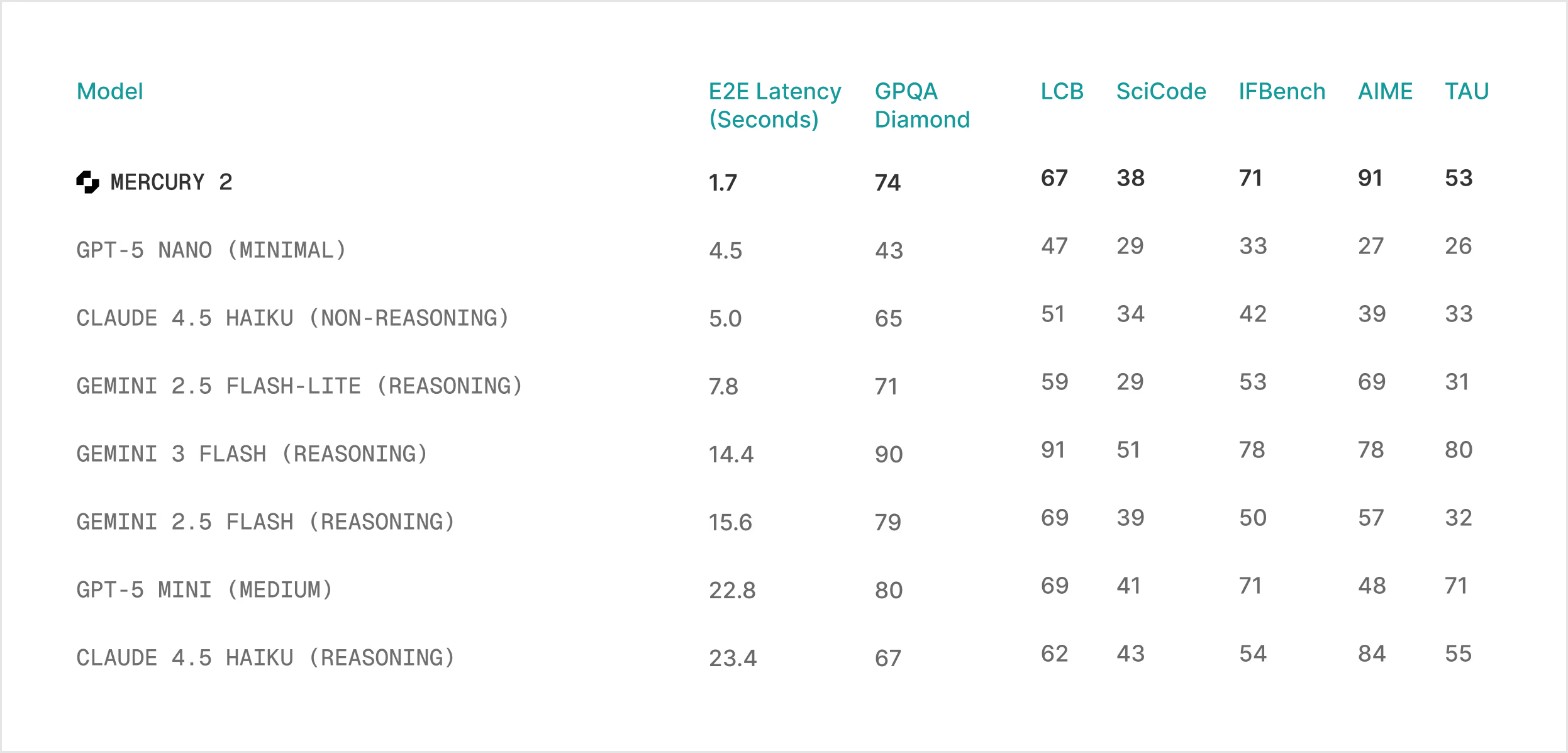
Our new Mercury 2 model is now available to all API users! With M2, you can build production applications that operate with unparalleled low latencies.
As a reminder, here is some of the key information about M2.
Speed: 1,009 tokens/sec on standard NVIDIA GPUs
Price: $0.25/1M input tokens · $0.75/1M output tokens · $0.025/1M cached input tokens
Quality: competitive with leading speed-optimized models
Features: tunable reasoning · 128K context · native tool use · schema-aligned JSON output
For now, you can access the model via our API platform. Access through partners like OpenRouter will follow soon.
Best,
The Inception Team