Hey, Happy New Year! A new year is always an excellent opportunity to learn something new. How about how to make your analytics queries fast? Today's newly released chapter is my favourite feature of TimescaleDB: Automatic pre-computation of results. Because what's faster than a perfectly optimized query? One that must barely load any data at all because it is already pre-computed - and kept up-to-date automatically.
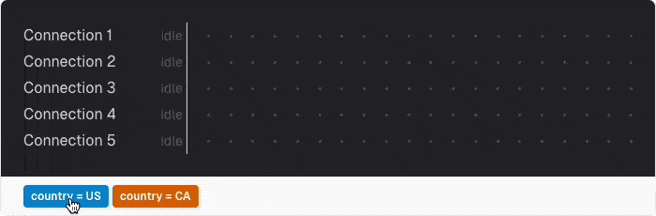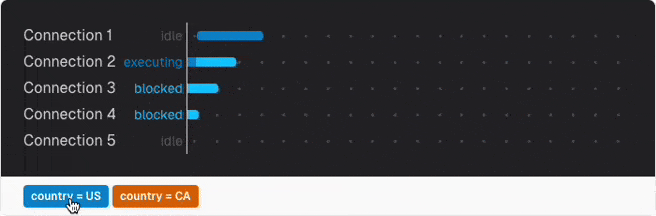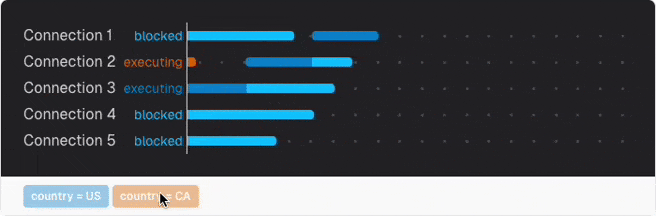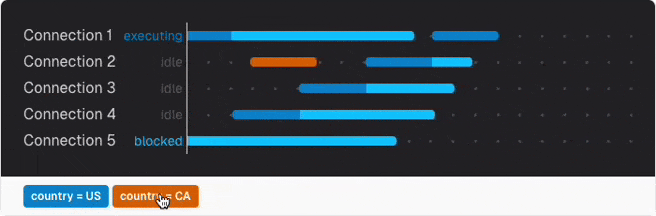
No matter how well you optimize an analytics query and schema, analyzing TBs of data will take some time. Too long if a user expects instant results. So your first idea may be creating special summary tables with pre-computed data. But this will fail very fast as only one connection can update the same row at a time. Every further query is blocked from execution until the others finish first.
You can get a feeling of this with the query locking simulator in this chapter.
TimescaleDB solves the locking issue with a more sophisticated pre-computation approach, as it's a PostgreSQL extension and has therefore access to PostgreSQL's internal workings.
With these two short SQL statements, you define the query that should pre-compute and the interval over which it does so. And it will only pre-compute stuff that changed since the last run. It is pretty magical.
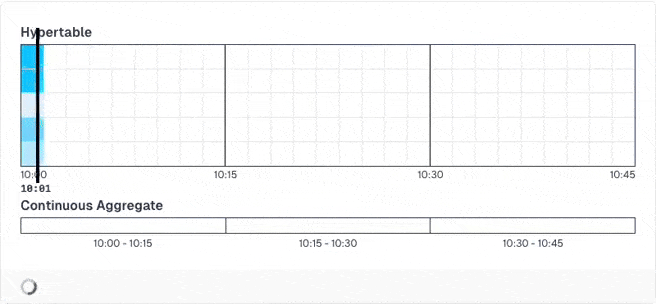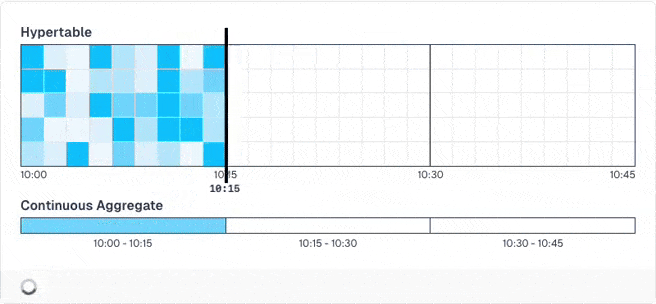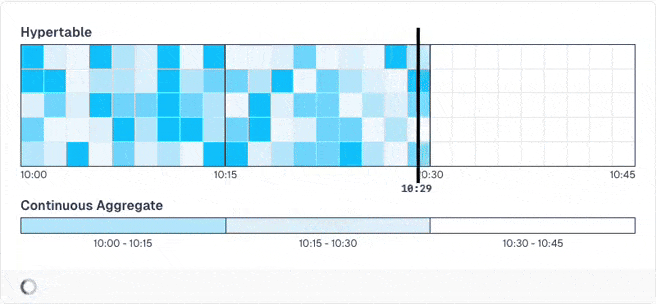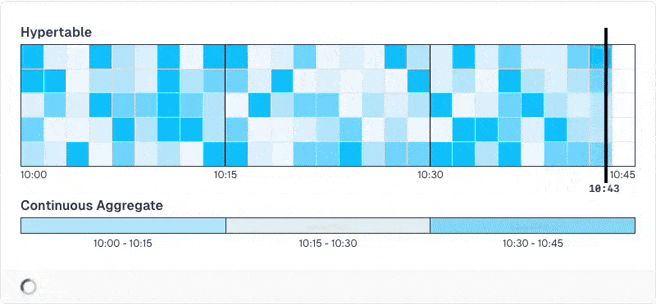
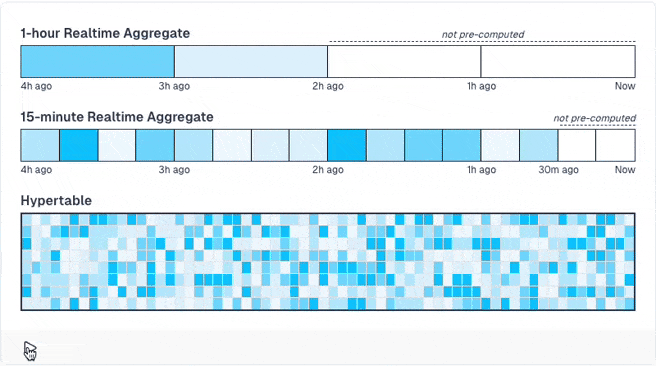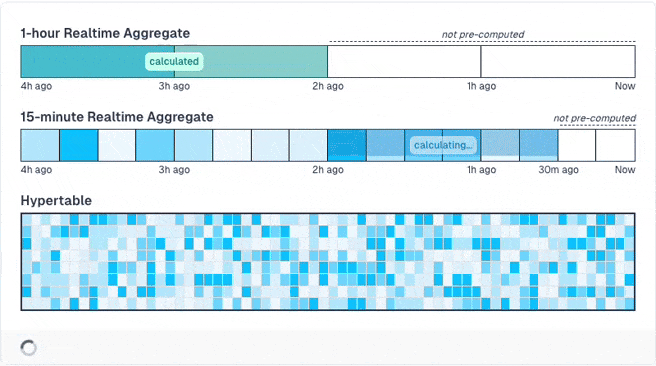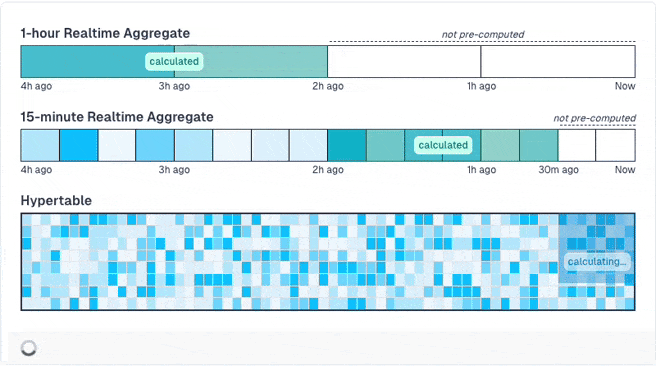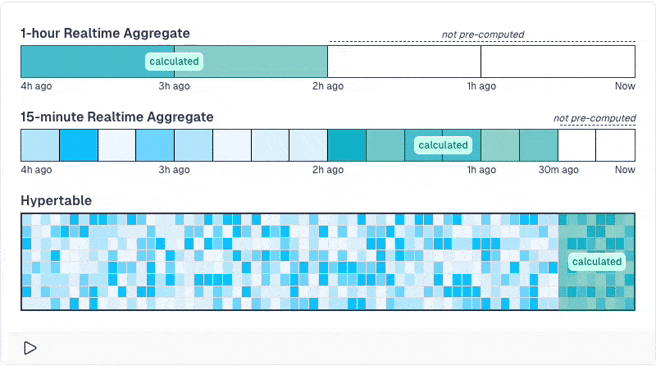
Obviously, those pre-computed results may be stale until the next run, when the data is recomputed. If you don't want this, you can activate a special mode that is groundbreaking: You can define that the newest data (e.g. the past hour) is never pre-computed as it changes quite often and will always be stale. Then, TimescaleDB only pre-computes older data. When you query the results, it merges the pre-computed results with live calculations for the new data.
And you don't have to do anything for this!
You can even build hierarchical pre-computed results that build on others to minimize the amount of rows that must be computed live.
That's a rough overview of the course's chapter but it describes the main idea. Learn about continuous aggregates and the performance benefits pre-computation will bring to your analytics without any effort. And all the different use cases TimescaleDB thought about by giving you a lot of flexibility. If that sounds interesting to you, please take a look at it and let me know what you think!
I hope you learn a lot
Tobias