|
How Coinbase made incident investigations 72% faster (Sponsored)
 |
Writing code is no longer the bottleneck. Instead, engineering orgs spend 70%+ of their time investigating incidents and trying to debug the sh** out of prod.
Engineering teams at Coinbase, DoorDash, Salesforce, and Zscaler use Resolve AI’s AI SRE to help resolve incidents before on-call is out of bed and to optimize costs, team time, and new code created with production context.
Download the free buyer’s guide to learn more about the ROI of AI SRE, or join our online FinServ fireside chat on Jan 22 with eng leaders at MSCI and SoFi to hear how large-scale institutions are evaluating and implementing AI for prod in 2026.
Disclaimer: The details in this post have been derived from the details shared online by the Uber Engineering Team. All credit for the technical details goes to the Uber Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When you open the Uber app to request a ride, check your trip history, or view driver details, you expect instant results. Behind that seamless experience lies a sophisticated caching system. Uber’s CacheFront serves over 150 million database reads per second while maintaining strong consistency guarantees.
In this article, we break down how Uber built this system, the challenges they faced, and the innovative solutions they developed.
Why Caching Matters
Every time a user interacts with Uber’s platform, the system needs to fetch data like user profiles, trip details, driver locations, and pricing information. Reading directly from a database for every request introduces latency and creates a massive load on database servers. When you have millions of users making billions of requests per day, traditional databases cannot keep up.
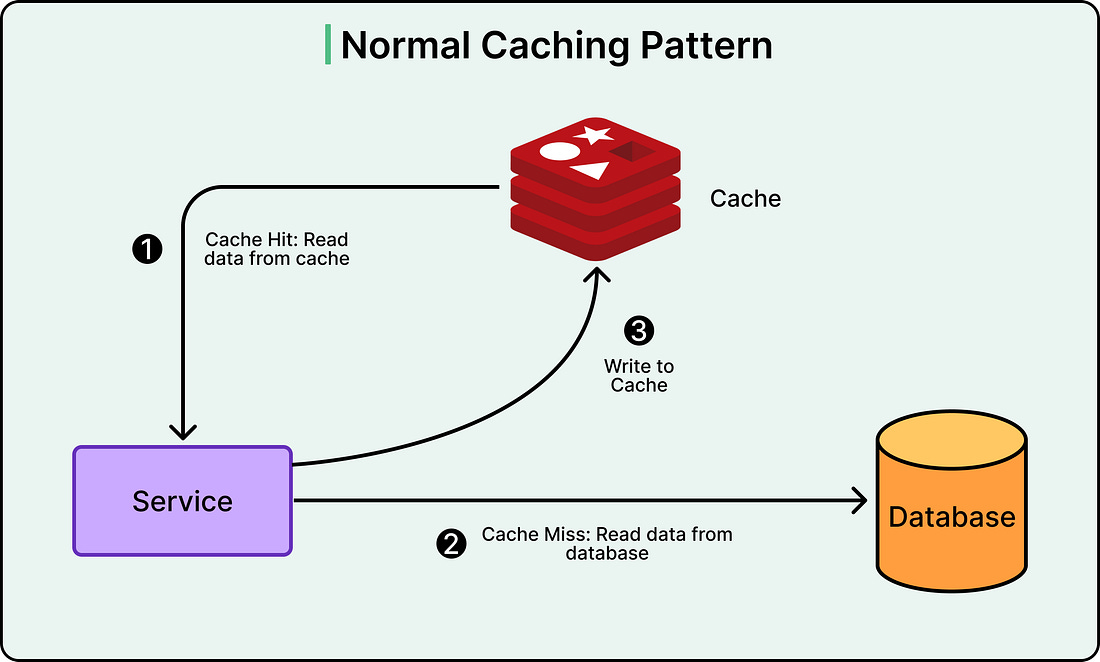
Caching solves this by storing frequently accessed data in a faster storage system. Instead of querying the database every time, the application first checks the cache. If the data exists there (a cache hit), it returns immediately. If not (a cache miss), the system queries the database and stores the result in cache for future requests.
See the diagram below:
 |
Uber uses Redis, an in-memory data store, as their cache. Redis can serve data in microseconds compared to milliseconds for database queries.
[Coderabbit]
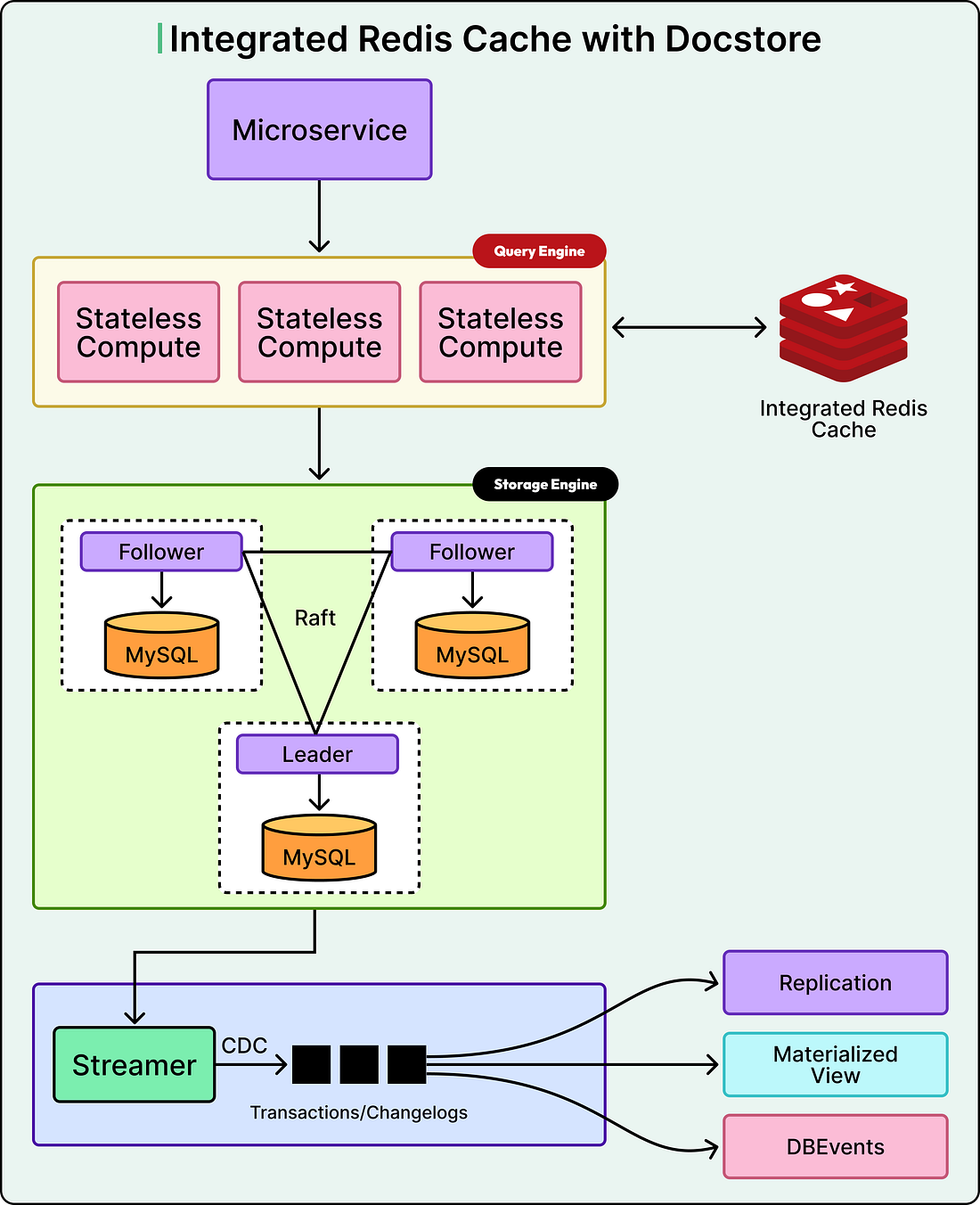
The Architecture: Three Layers Working Together
Uber’s storage system, called Docstore, consists of three main components.
The Query Engine layer is stateless and handles all incoming requests from Uber’s services.
The Storage Engine layer is where data actually lives, using MySQL databases organized into multiple nodes.
CacheFront is the caching logic implemented within the Query Engine layer, sitting between application requests and the database.
 |
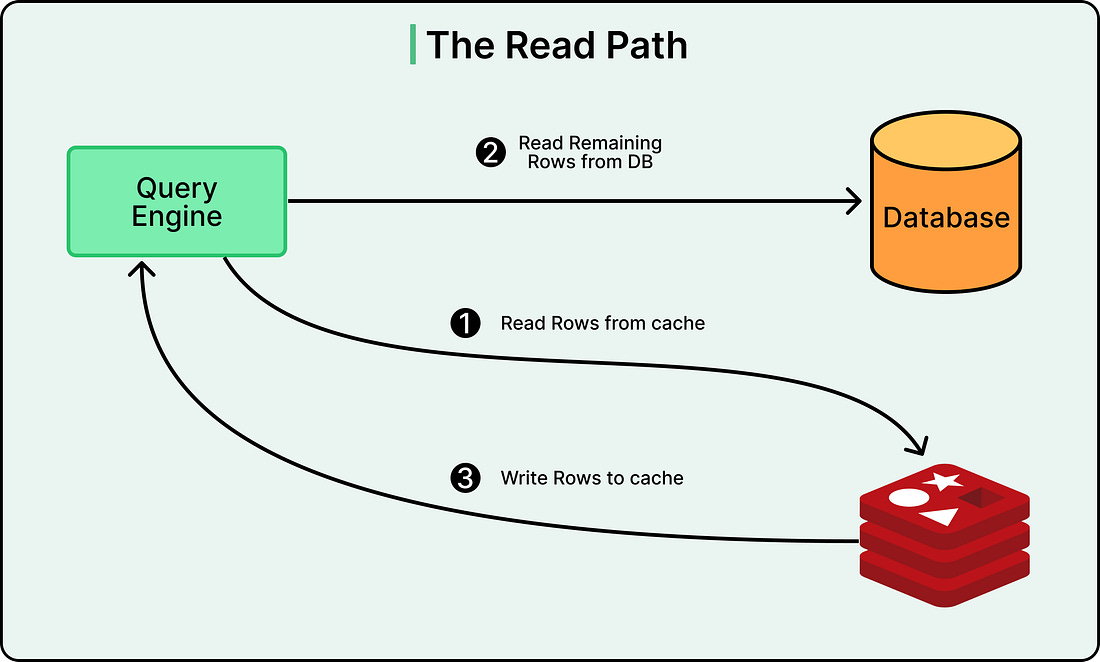
The Read Path
When a read request comes in, CacheFront first checks Redis. If the data exists in Redis, it returns immediately to the client. Uber achieves cache hit rates above 99.9% for many use cases, meaning only a tiny fraction of requests need to touch the database.
If the data does not exist in Redis, CacheFront fetches it from MySQL, writes it to Redis, and returns the result to the client. The system can handle partial cache misses as well. For example, if a request asks for ten rows and seven exist in cache, it only fetches the missing three from the database.
 |