|
 |
Prompt Control – The mind behind the machine — Part 3
To stops your local AI from talking… too much, you don't need a better mode. You need to find a better way to to talk to your favorite one.
 |
I am a huge fan of Local AI: means that I test to the limit my crappy GPU-poor laptop to see how far I can use a Large Language Model without relying on internet connection and cloud APIs.
I decided to test again how good can a Small Language model be in support my python programming: a sort of…
AI that help me programming AI application
In this article I will report few points to be considered if you decide to do the same: what model to use, what kind of resources you need (VRAM/RAM), and as well drawbacks like context window size and system prompt requirements.
This is the app I was trying to build:
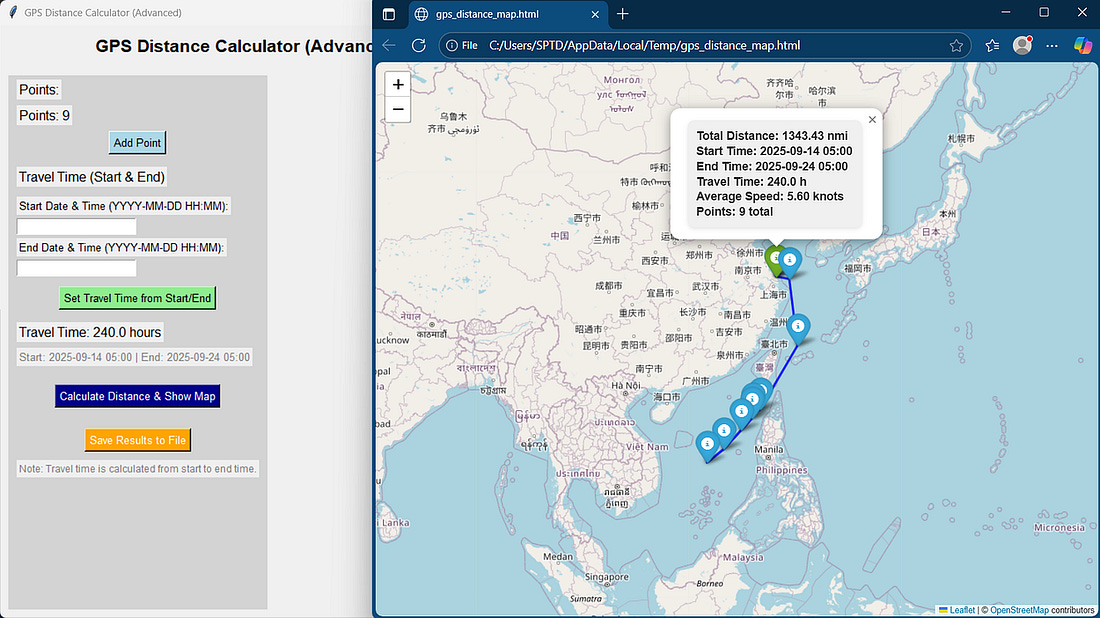 |
Honestly the app itself is not that important, but the process to arrive to completion is interesting.
If you want to have a look at the code, here is the final GitHub repository:
 |
So, after last two weeks, we know that a system prompt is a rulebook.
Today we will try to understand how we can use it as a real operating system for our LLM applications.
To recap
Part 1 - The importance of system messages with your local AI DONE
Part 2 - Prompt engineering Vs System design DONE
Part 3 - The hidden Logic: teach local AI to follow your rules <-- WE ARE HERE
Part 4 - System prompt to produce structured outputs: no more guessing.If you are already bored to death… here the main issue I found: I will explain in the article how to solve them.
- The first prompt is the key for success
- you will find yourlsef with truncated code
- Functions and Classes will make the code efficient (but readable?)
- the AI will repeat everything with a lot of explanations
- you need to test the code every time, and copy/paste the errors
again to fix the broken parts
- Qwen3-4b-instruct works as good as Qwen3-235B-A22B-2507Buckle up and follow me.
 |
My setup
I always serve local LLM with llama.cpp server. It is easy to use, comes with pre-compiled binaries for different Operating Systems, and it is fully compliant with OpenAI standard API endpoints.
The model I am using is, in my opinion, the best open-source, non-reasoning Small Language Model at the moment: Qwen3–4B-Instruct-2507.
We introduce the updated version of the Qwen3–4B non-thinking mode, named Qwen3–4B-Instruct-2507, featuring the following key enhancements:
Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage.
Substantial gains in long-tail knowledge coverage across multiple languages.
Markedly better alignment with user preferences in subjective and open-ended tasks, enabling more helpful responses and higher-quality text generation.
Enhanced capabilities in 256K long-context understanding
Running this model without a dedicated GPU (or without Intel Accelerators and NPU) is possible, but you have to expect slow speed… But the accuracy is outstanding!
If you want to do the same:
1️⃣ download in a project directory (something like llama-server) the llama.cpp binaries (llama-b6569-bin-win-vulkan-x64.zip) and unpack the ZIP archive there.
NOTE: I am using Windows, so I recommend to download the x64 version. If you have the Vulkan drivers installed the win-vulkan version is the best, because it can handle your dedicated or integrated GPU seamlessly.
2️⃣ Then download the GGUF weights Qwen3–4B-Instruct-2507.i1-Q4_K_S.gguf for the model from here. Put it in the same llama-server directory.
3️⃣ From the terminal run:
.\llama-server.exe -m .\Qwen3-4B-Instruct-2507.i1-Q4_K_S.gguf -c 8192 -fa on -ngl 0This will start the model, create compatible openai API endpoints, with a context window of 8k tokens and 0 layers offloaded to GPU.
4️⃣ Now you can open your browser at http://127.0.0.1:8080 and have a modern, easy to use chat interface.