|
|
|
Hey Developers,
Welcome to this week’s new(s)line report.
Cloudflare's 'content independence day' marks a potential shift in the nature of web content and its relationship with AI; Chai Discovery showcases AI-generated antibodies; and Apple considers going to competitor models for Siri.
|
|
Today’s headlines:
|
-
Cloudflare declares ‘Content Independence Day’ with rollout of AI crawler countermeasures
-
Chai-2 model heralds new age in drug development with orders of magnitude improvement to antibody discovery
-
Apple in talks with Anthropic, OpenAI to incorporate their models into Siri
|
|
Let’s dive right in.
|
|
|
|
|
|
|
 |
|
Image credit: Cloudflare
|
|
|
Amidst all the recent hubbub and legal cases about web scraping and training data, Cloudflare makes a bold proclamation:
It's “Content Independence Day” according to the Cloud giant, which provides network security services for some 20% of the internet.
What does it mean? Cloudflare is implementing protections from AI crawlers – preventing them from ingesting content without explicit permission.
In the long term, Cloudflare aims to implement a ‘micro-payment’ system where publishers can charge a small fee for automated systems to access content.
In their recent blog post, Cloudflare talks about the changing landscape of the web, contrasting the old model where search engines would copy content for search in exchange for traffic with the modern practice of AI summaries.
The blog claims that it’s now between 750 and 30000 times more difficult for content creators to get organic traffic – a significant threat to ad revenue and subscriptions for most smaller sites.
Giving online publishers a new way to monetise their content for AI might give many smaller web businesses a lifeline, and positions Cloudflare as a gatekeeper for online data.
This move will allow sites to set individual prices through pay-per-crawl, and many media outlets (Condé Nast, The Atlantic, Time etc.) have already joined the initiative.
With the continued increase in agentic AI and autonomous scraping, this could be exactly what the internet needs to preserve its magic.
Though doubtless some AI leaders will have strong feelings about this.
|
|
|
|
|
|
|
 |
|
Image credit: Chai Discovery
|
|
|
Chai Discovery – a medical AI company backed by OpenAI – just announced its Chai-2 model, which is capable of creating functional antibodies for drug development.
The company’s mission is to transform biology from a science into engineering. It’s a bold mission statement, but this model proves that they can walk the walk
The models boasts a 20% “hit rate”. That doesn’t sound huge, but considering previous methods typically achieve lower than 0.1% this shift is several orders of magnitude of improvement.
Typically, antibody discovery is a very long (months to years) and arduous process, requiring the screening of millions of candidates – Chai-2 delivered results in just two weeks.
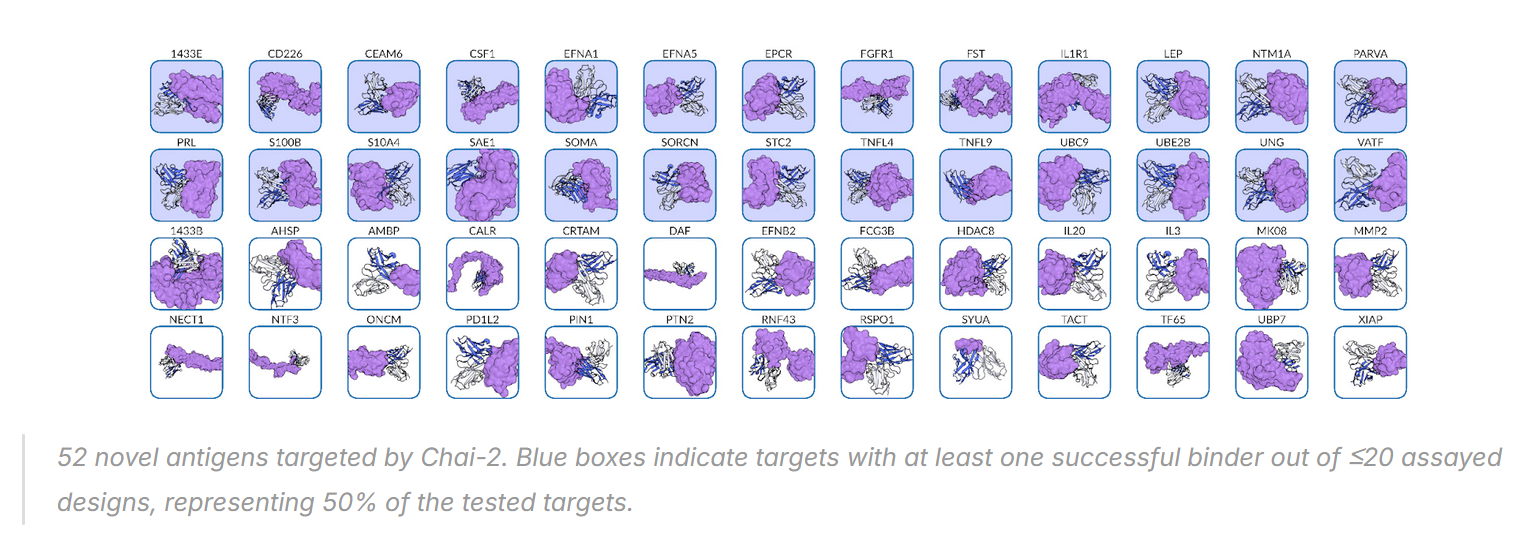
Researchers tested it on 52 different ‘disease targets’.
Chai found successful treatments for half of them by testing just 20 candidates each.
Crucially, the model does not need to rely on the collection of samples - it works ‘from scratch’, going backwards from the target’s molecular structure.
The lab is opening up ‘early access’ to academic and enterprise research institutions, though they will prioritise customers who fit with their Responsible Deployment Policy, prioritising use cases that have a positive impact on human health.
(This statement does imply that this technology could have more nefarious uses. Food for thought…)
That said, this milestone means that the door is now opened to seeking treatments to diseases that were either too complex or not cost-effective to research in the past.
There is a tendency for big medical breakthroughs to make waves in headlines and then quickly fade into obscurity as they get bogged down in testing or big pharma bureaucracy – but we can hope that this model and others like it will accelerate drug discovery and distribution in the coming decades.
|
|
|
|
|
|
|
 |
|
Image credit: Apple
|
|
|
Apple is reportedly in talks with Anthropic and OpenAI to use their models for the next generation of Siri – a significant shift in their AI policy.
The software giant has approached competitors to design tailored versions of their large language models that can be deployed on Apple’s infrastructure for testing – though of course this is not confirmation that either model will be used.
Having two AI firms in the race allows Apple to negotiate a better price, with reports that Apple was quoted multi-billion annual licence fees to use Anthropic.
So why abandon its in-house models?
There have been numerous setbacks with Apple’s AI division, and Siri’s market share is largely dependent on iPhone users, with the assistant struggling to catch up to Amazon Alexa and Google Assistant who both have a much larger market share for smart devices.
The new version of Siri is not scheduled to launch until 2026, giving Apple a lot of runway to get its ducks in a row (if you’ll forgive a mixed metaphor).
But time is money, and with the staggering speed of the AI industry it’s going to be very difficult to regain market share without offering a clear improvement not only over previous iterations but against competitors.
It’s no secret that Apple has been surprisingly quiet in the AI race, leaving many to wonder if they’re making some secret play internally or if they just aren’t engaging with it to the level of the other big players.
The fact that Apple is going to outside companies instead of using their in-house models seems to be a point in favour of the latter.
If it isn’t, there is some serious 4-d chess going on somewhere behind the scenes.
But it isn’t over until it’s over, and Apple is still one of the largest companies in the world – it may well have a few surprises left to show us.
|
|
|
|
|
Everything else in AI
|
|
Amazon deploys its 1 millionth robot, releases generative AI model, DeepFleet, for warehouse operations.
|
|
Baidu releases Ernie 4.5 - a new open-source model family that rivals DeepSeekR1 in many benchmarks..
|
|
X set to allow AI bots to write and post community notes on its social media platform.
|
|
OpenAI launches $10M custom AI consulting arm to build bespoke AI solutions for large enterprises.
|
|
Google is betting on fusion power with landmark deal to ‘pre-order’ 200MW of energy for the 2030s:.
|
|
Vibe-coding platform Lovable raises $150M with a $2B valuation.
|
|
|
|
|
|
|
|
|
React Devs - Don't go chasing waterfalls
|
|
Fetching data can be tricky – even with React.
One of the most common issues we see new React developers run into is Fetch Waterfalls, which is not as fun as it sounds.
This phenomenon happens when your fetch requests execute in series rather than in parallel – one request waiting on the output of another means that pages load slowly.
And that's without getting inot Race Conditions...
A lot of devs overuse React's useEffect hook, or worse, use it in ways that asren't useful, leading to poor performance
If you're an up-and-coming React dev who wants to get good fast and avoid all these common data fetching mistakes, then we have just the thing for you.
In React Data Fetching: Beyond the Basics we show you how to fetch data in a performant way without using a third party library.
If you enroll you'll learn:
- How React fetching and rendering works
- How to precache and fetch data from React components before they finish loading
- How to avoid network waterfalls and race conditions
- Mastery of different React hooks and best practices for their use
- This is a hands on course with code-along – so you're guaranteed to have a portfolio project by the end.
Sounds good? You can sign up here. Or not. I'm not your mother.
|
|
Join newline Pro and get access to all our premium articles, courses and books
|
|
|
|
|
|
That's all for now folks! Tune in next time for more news stories from the weird and wonderful world of AI.
|
|
See you soon,
|
|
The new(s)line editorial team
|
|
|
|
